Diagrama de temas
-
Diseño de bases de datos y clasificación de variables
-
1.1 Alcance de una base estructurada
Una base de datos es una colección estructurada de información que permite el almacenamiento, recuperación y gestión eficiente de datos. Según la American Psychological Association (2020), las bases de datos pueden ser clasificadas en diferentes tipos, como relacionales, NoSQL o en la nube, dependiendo de su estructura y propósito. Estas herramientas son fundamentales en diversos campos, incluyendo la investigación académica, la administración de empresas y el desarrollo de software, ya que facilitan el acceso a grandes volúmenes de información de manera organizada. En este contexto, es crucial comprender cómo se diseñan y utilizan las bases de datos para maximizar su utilidad y eficiencia en la toma de decisiones informadas.
1.1.1 Diseño de una base de datos
Diseñar una base de datos es un proceso que implica varios pasos para garantizar que los datos se almacenen de manera eficiente y se puedan recuperar fácilmente. A continuación, te presento un enfoque básico para diseñar una base de datos. Las bases de datos son sistemas diseñados para almacenar, gestionar y recuperar información de manera eficiente. En el entorno empresarial, resultan esenciales para registrar información relacionada con clientes, productos, ventas, entre otros aspectos fundamentales para las operaciones diarias. Estos sistemas pueden variar en complejidad, desde bases de datos sencillas como tablas en Excel, hasta sistemas avanzados manejados por motores como SQL Server o MySQL. La principal ventaja de usar bases de datos radica en su capacidad para gestionar grandes volúmenes de información de forma estructurada, facilitando su análisis (Connolly & Begg, 2014).
Excel es una herramienta ampliamente utilizada para gestionar bases de datos pequeñas o medianas. A través de sus funciones como tablas dinámicas, gráficos y fórmulas avanzadas, Excel permite a los usuarios organizar, filtrar y analizar datos de manera efectiva. Es ideal para gestionar datos cuando el volumen no es muy grande y la estructura es relativamente simple. Además, Excel facilita la conexión a bases de datos externas para complementar su funcionalidad, aunque presenta limitaciones en cuanto al manejo de grandes volúmenes de información (Walkenbach, 2013).
Por su parte, Power BI es una herramienta de análisis y visualización de datos que se destaca por su capacidad para gestionar grandes volúmenes de información y conectarse a múltiples fuentes de datos, incluyendo bases de datos relacionales y archivos de Excel. Power BI permite la creación de informes interactivos y dashboards, proporcionando una visión clara y en tiempo real del desempeño de una organización. Esta herramienta se convierte en una opción ideal para automatizar y actualizar análisis en bases de datos complejas (Russo & Ferrari, 2016).
a. Definir el Propósito de la Base de Datos
Cuando se va diseñar la base de datos nos debemos preguntar: ¿Qué tipo de datos necesitas almacenar? Al respondernos a esta pregunta se logrará determinar las posibles a considerar en la base
Para responder a la pregunta ¿Qué tipo de datos necesitas almacenar?, es importante primero identificar el propósito y el contexto de uso de los datos. En una organización, los datos comunes incluyen información de clientes, como nombres, direcciones y contactos; datos financieros, como facturas y transacciones; inventarios, como productos y cantidades; y datos operacionales, como órdenes de compra y ventas (Connolly & Begg, 2014). Además, dependiendo del sector, podrían necesitarse almacenar datos más específicos, como registros médicos, reportes de desempeño o datos de producción. El tipo de datos también puede clasificarse en estructurados y no estructurados. Los datos estructurados incluyen información que puede organizarse en tablas, como números y fechas, mientras que los datos no estructurados abarcan formatos como correos electrónicos, imágenes y documentos. El almacenamiento de estos datos debe planificarse según su uso previsto y la capacidad de análisis requerida (Elmasri & Navathe, 2011).
¿Quién utilizará la ? En base a quién utilizará la base , te permitirá determinar que variables se debe considerar al momento de construir un reporte.
La base de datos será utilizada principalmente por aquellos usuarios que necesiten acceder, gestionar o analizar grandes volúmenes de información para tomar decisiones informadas. Estos usuarios pueden ser empleados de diferentes departamentos de una organización, como finanzas, ventas, marketing o recursos humanos. Dependiendo de la naturaleza de la base de datos, los analistas de datos, gerentes o personal operativo también pueden utilizarla para obtener información precisa y actualizada. Además, se espera que los encargados de TI o administradores de sistemas gestionen y mantengan la base de datos, asegurando su correcto funcionamiento y seguridad (Connolly & Begg, 2014).
Aprende más
Para conocer más sobre ¿Quién utilizará la base de datos?, puedes ver el siguiente video ¡Accede aquí!
b. Recopilar e identificar variables
Luego que has determinado la posible base de datos, debes ahora identifica las variables y sus atributos. Por ejemplo, si estás diseñando una base de datos para una tienda en línea, podrías tener variables como Productos, Clientes y Órdenes.
c. Identificar Atributos
Un atributo de una variable se refiere a una característica o propiedad específica que describe esa variable. En el contexto de la investigación, los atributos pueden ser cualitativos, como el color o el género, o cuantitativos, como la edad o la altura (Trochim, 2021). Estos atributos son fundamentales para la recolección y análisis de datos, ya que permiten categorizar y cuantificar la información, facilitando así la interpretación de los resultados. La identificación adecuada de los atributos de una variable es esencial para garantizar la validez y la confiabilidad de cualquier estudio, ya que influye en cómo se diseñan los instrumentos de medición y se llevan a cabo los análisis estadísticos.
- Productos
- ID (clave primaria)
- Nombre
- Descripción
- Precio
- Stock
- Clientes
- ID (clave primaria))
- Nombre
- Teléfono
- Órdenes
- ID (clave primaria)
- ID del Cliente (clave foránea)
- Fecha de Orden
- Total
- Definir Relaciones
d. Definir Relaciones
La relación entre tablas en bases de datos es un concepto clave en la organización y estructuración de la información. Las bases de datos relacionales, que son ampliamente utilizadas, están construidas sobre el principio de dividir la información en tablas interrelacionadas. Cada tabla contiene datos sobre una entidad específica, como personas, productos, o transacciones, y las relaciones entre estas tablas permiten establecer vínculos que representan la interconexión entre las entidades de la vida real. A través de estas relaciones, se pueden realizar consultas y obtener información compleja de manera eficiente. Para entender mejor este concepto, es esencial explorar los tipos de relaciones o cardinalidades que existen y cómo influyen en el diseño de bases de datos.
Concepto de relación entre tablas.
Una relación entre tablas implica que dos o más tablas de una base de datos están conectadas mediante un campo común o clave. Este campo común es, generalmente, una clave primaria en una de las tablas y una clave foránea en la otra. La clave primaria es un identificador único que distingue cada registro dentro de una tabla, mientras que la clave foránea es un campo que se refiere a la clave primaria de otra tabla. Estas relaciones permiten la integridad referencial, lo que significa que los datos en una tabla están alineados con los datos relacionados en otras tablas. Por ejemplo, en un sistema de ventas, una tabla de clientes podría estar relacionada con una tabla de pedidos, de modo que cada pedido esté vinculado a un cliente específico.
Tipos de relaciones o cardinalidades
La cardinalidad en bases de datos describe la naturaleza de la relación entre los registros de las tablas involucradas. Existen tres tipos principales de relaciones o cardinalidades:
1. Relación uno a uno (1:1)
En una relación uno a uno, cada registro en la primera tabla está relacionado con un solo registro en la segunda tabla, y viceversa. Este tipo de relación es menos común y, por lo general, se utiliza cuando una entidad se divide en varias tablas por razones de eficiencia o seguridad. Por ejemplo, si tenemos una tabla de empleados, podríamos tener otra tabla de información confidencial con datos sensibles, y cada empleado estaría vinculado a un solo registro en la tabla confidencial.
El uso de relaciones 1:1 puede ayudar a organizar los datos cuando es necesario mantener la privacidad de ciertos aspectos o cuando se requiere que diferentes departamentos accedan a conjuntos de datos diferentes de la misma entidad.
2. Relación uno a muchos (1:N)
En una relación uno a muchos, un registro en la primera tabla puede estar relacionado con muchos registros en la segunda tabla, pero cada registro en la segunda tabla solo puede estar relacionado con un registro en la primera tabla. Este es uno de los tipos de relaciones más comunes en bases de datos. Un ejemplo clásico es la relación entre clientes y pedidos. Un cliente puede hacer muchos pedidos, pero cada pedido solo pertenece a un cliente.
Este tipo de relación es útil cuando una entidad tiene varias instancias asociadas con ella. En el caso anterior, un cliente puede tener muchos pedidos, pero no al revés, lo que refleja cómo las entidades de la vida real interactúan en una base de datos. La clave primaria del cliente aparecería como clave foránea en la tabla de pedidos, estableciendo así la relación entre ambas tablas.
3. Relación muchos a muchos (N:M)
En una relación muchos a muchos, múltiples registros en la primera tabla pueden estar relacionados con múltiples registros en la segunda tabla. Este tipo de relación es más complejo y generalmente requiere una tabla intermedia o de asociación para implementarse de manera efectiva. Un ejemplo clásico es la relación entre estudiantes y cursos en una universidad. Un estudiante puede inscribirse en muchos cursos, y cada curso puede tener muchos estudiantes.
Una de las características de trabajar con grandes volúmenes de datos, es que las tablas se van relacionando unas con otras ya que, por ejemplo:
Tipo de Relación Descripción Ejemplo Uno a uno En una relación uno a uno, un registro en una tabla se asocia con un único registro en otra tabla Un empleado y su identificación personal Uno a muchos En una relación uno a muchos, un registro en una tabla puede asociarse con múltiples registros en otra tabla Un autor y sus libros publicados Tabla 1: Definición de relaciones HeaderContent- Un cliente puede tener muchas órdenes, pero una orden pertenece a un solo cliente (relación uno a muchos).
- Un producto puede estar en muchas órdenes, y una orden puede contener muchos productos (relación muchos a muchos).
Aprende más
Para conocer más sobre los tipos de relación, puedes ver el siguiente video ¡Accede aquí!
1.1.2 Validación de variables
Luego de que ya tenemos definido el tipo de base de datos a construir y determinado las variables a utilizar en la base, el siguiente paso es determinar la validación, La validación de variables se refiere al proceso de garantizar que las variables utilizadas en una investigación o estudio sean precisas y relevantes para los objetivos establecidos. Según Creswell (2014), este proceso implica verificar que las mediciones sean consistentes y que los conceptos se representen adecuadamente en los instrumentos de recolección de datos. La validación puede incluir técnicas como pruebas de confiabilidad, análisis estadísticos y revisiones por expertos, lo que asegura que los resultados obtenidos sean válidos y aplicables al contexto de estudio. La importancia de la validación radica en su capacidad para fortalecer la integridad del estudio, proporcionando confianza en que las conclusiones derivadas son efectivamente representativas de la realidad que se investiga.
En la validación de variables se debe considerar los siguientes aspectos:
- Tipo de Datos: Asegúrate de que la variable sea del tipo esperado (ej. entero, cadena, fecha).
Tipo de Relación Descripción Ejemplo Entero representa números enteros, sin decimales 5, -3, 42 Cadena Conjunto de caracteres, que pueden incluir letras, números y símbolos "Hola", "2023", "Nombre del usuario" Fecha Representa información sobre fecha y hora "2024-09-29", "15/08//2023", "03:45PM" Tabla 2: Tipos de datos - Rango de Valores: Verifica que los valores estén dentro de un rango aceptable (ej. edad entre 0 y 120).
- Formato: Comprueba que los datos cumplan con un formato específico (ej. correos electrónicos, números de teléfono).
- Longitud: Valida que las cadenas no excedan una longitud máxima o sean suficientemente largas.
- Valores Permitidos: Asegúrate de que los valores estén en una lista de opciones permitidas (ej. días de la semana).
- Presencia: Verifica que los campos obligatorios no estén vacíos.
HeaderContent1.1.3 Creación de la tabla (Excel)
Al momento ya tienes planificado el tipo de base datos a presentar, las variables que van a formar dicha tabla y su respectiva validación, ahora vamos a construir la tabla y para ello puedes seguir las siguientes recomendaciones:
- a. Abrir Excel
- b. Crear la Estructura de la Tabla
- c. Ingresar Datos
- d. Aplicar Validaciones
- e. Guardar la Base de Datos
- Abrir Microsoft Excel y crea un nuevo archivo.
- En la primera fila, escribe los nombres de las columnas que representarán los atributos de tus
datos
- Comienza a ingresar los datos en las filas bajo los encabezados. Asegúrate de mantener el
formato consistente para cada columna.
- Para asegurar la calidad de los datos, puedes aplicar validaciones. Selecciona una columna y ve
a Datos > Validación de datos.
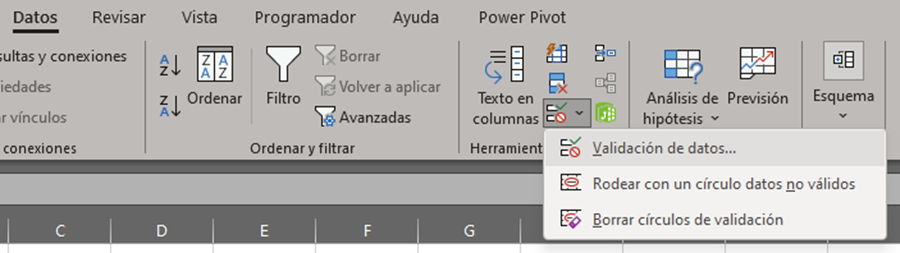
Figura 1: Validación de datos Configura las reglas según tus necesidades , a continuación, comparto un resumen de las opciones de validación:
Tipo de Relación Descripción ejemplo Validación de datos Permite restringir los tipos de datos que se pueden ingresar Solo permiten números enteros, listas desplegables Longitud del Texto Establece límites en la cantidad de caracteres que se pueden ingresar. Máximo de 10 caracteres en un campo de texto. Rango de Fechas Restringe las fechas que se pueden introducir en una celda. Solo permitir fechas entre el 01/01/2020 y el 31/12/2023. Números Enteros Permite definir que solo se ingresen números enteros. Solo aceptar valores entre 1 y 100. Listas Desplegables Ofrece opciones predefinidas para seleccionar en lugar de ingresar manualmente. Selección de productos de una lista. Formato Personalizado Define un formato específico para los datos ingresados. Ingresar números como códigos postales (ej. 12345). Tabla 3: Opciones de validación - Guarda el archivo con un nombre descriptivo y en el formato deseado (por ejemplo, `.xlsx`).
1.2 Clasificación de variables
La clasificación de variables es un aspecto fundamental en la investigación, ya que permite categorizar y entender mejor los datos recolectados. Según Creswell (2014), las variables pueden clasificarse en diferentes tipos, tales como variables independientes y dependientes, donde las primeras son aquellas que se manipulan para observar su efecto en las segundas. Además, las variables pueden ser cualitativas, que describen características o atributos, o cuantitativas, que representan datos numéricos. Dentro de estas categorías, las variables cualitativas se dividen en nominales y ordinales, mientras que las cuantitativas se clasifican en discretas y continuas. Esta clasificación es esencial para el diseño de estudios, el análisis de datos y la interpretación de resultados, ya que proporciona un marco claro para abordar las preguntas de investigación.
Tipo de Relación Descripción Ejemplo Numéricas Variables que representan cantidades o valores medibles. - Discretas Toman valores enteros y específicos. No admiten decimales. Número de hijos, cantidad de autos. - Continuas Pueden tomar cualquier valor dentro de un rango, incluyendo decimales. Estatura, peso, temperatura. Categóricas (Cualitativas) Variables que representan categorías o grupos, no numéricos. - Nominales Categorías sin orden específico. Color de ojos, país de origen. - Ordinales Categorías con un orden específico. Nivel educativo, nivel de satisfacción. Tabla 3: Opciones de validación HeaderContentVamos observando a detalle cada tipo de variable:
1.2.1 Variables numéricas
Las variables son elementos fundamentales en la investigación cuantitativa, ya que representan cualquier característica o atributo que puede ser medido y que puede asumir diferentes valores. En términos estadísticos, las variables permiten identificar y analizar relaciones entre fenómenos. Dependiendo de cómo se midan o clasifiquen, las variables pueden ser cualitativas o cuantitativas. Las primeras se refieren a características no numéricas, como el género o la raza, mientras que las segundas se refieren a cantidades numéricas, como la altura o el peso (Hernández et al., 2014).
Las variables tienen varias propiedades importantes. Una de ellas es la validez, que refiere a la capacidad de una variable de medir exactamente lo que se propone medir. Por ejemplo, una variable que mide el nivel de estrés debe estar relacionada directamente con indicadores de estrés, como la presión arterial o los niveles de cortisol. Otra propiedad es la confiabilidad, que se refiere a la consistencia de los resultados cuando la variable se mide repetidamente en condiciones similares (Mertens, 2015). La precisión y la replicabilidad son esenciales para garantizar que los estudios sean fiables.
Las variables numéricas son aquellas que representan cantidades o valores medibles, y se dividen en dos tipos: discretas y continuas. Las variables discretas solo pueden tomar valores enteros, es decir, números específicos que no admiten fracciones ni decimales (por ejemplo, el número de hijos o la cantidad de automóviles en una familia). Por otro lado, las variables continuas pueden asumir cualquier valor dentro de un intervalo, incluidas fracciones y decimales. Estas variables representan mediciones que pueden tomar una infinita cantidad de valores posibles, como la estatura, el peso o la temperatura (Field, 2018).
Variables Discretas:
Las variables numéricas discretas son aquellas que solo pueden asumir valores enteros y específicos, sin admitir fracciones ni decimales. Estas variables se utilizan para contar elementos o eventos, y cada valor representa una cantidad finita. Un ejemplo típico de una variable discreta es el número de hijos en una familia, ya que solo se pueden tener un número entero de hijos, como 0, 1 o 2, pero no fracciones de hijos. De manera similar, otras variables discretas incluyen la cantidad de automóviles en un hogar o el número de estudiantes en una clase. A diferencia de las variables continuas, que pueden tomar cualquier valor dentro de un rango, las variables discretas están limitadas a un conjunto específico de resultados (Creswell & Creswell, 2018).
Variables Continuas:
Las variables numéricas continuas son aquellas que pueden tomar cualquier valor dentro de un rango específico, incluidas fracciones y decimales. A diferencia de las variables discretas, las continuas representan mediciones que pueden variar infinitamente entre dos puntos. Ejemplos comunes de variables continuas incluyen la estatura, el peso y la temperatura, donde no existen restricciones para los valores intermedios. Por ejemplo, una persona puede medir 1.75 metros o pesar 68.9 kilogramos. Estas variables permiten una mayor precisión en la medición, ya que pueden asumir valores infinitos entre dos números (Pagano, 2018).
1.2.2 Variables categóricas
Las variables categóricas, también conocidas como cualitativas, son aquellas que representan cualidades o características y se clasifican en grupos o categorías mutuamente excluyentes. Estas variables no tienen un valor numérico asociado, sino que identifican diferentes categorías dentro de un conjunto de datos. Se dividen en dos tipos:
Las variables nominales son un tipo de variable cualitativa que se utiliza para clasificar o categorizar datos en grupos o categorías que no tienen un orden específico. Estas variables simplemente indican la presencia o ausencia de una característica, pero no permiten establecer una jerarquía entre los valores. Ejemplos comunes de variables nominales incluyen el género, el estado civil o la nacionalidad. Al no tener una secuencia natural, los valores de las variables nominales no pueden ser comparados en términos de mayor o menor, sino que son considerados equivalentes entre sí (Martínez, 2016).
En el análisis estadístico, las variables nominales juegan un papel importante, ya que permiten clasificar y organizar los datos en diferentes categorías. Estas variables son usualmente representadas mediante códigos numéricos o etiquetas de texto que ayudan a identificarlas de manera eficiente, aunque los números asignados no implican ningún tipo de orden. El análisis de estas variables se realiza generalmente utilizando frecuencias o proporciones, ya que no es posible aplicar operaciones matemáticas como la media o la mediana (Levin & Rubin, 2017).
Nominales: Las categorías no tienen un orden inherente. Ejemplos:- Color de ojos (azul, verde, marrón).
- Género (masculino, femenino).
Las variables nominales no tienen un orden inherente entre las categorías, como el color de ojos o el país de origen. En cambio, las variables ordinales tienen un orden definido, aunque las diferencias entre categorías no son medibles, como el nivel educativo (primaria, secundaria, universitaria) o el nivel de satisfacción (bajo, medio, alto) (Babbie, 2021). A continuación, se da un resumen consolidado de estos tipos de variables
1.2.3 Variables ordinales
Ordinales: Las categorías tienen un orden o jerarquía, pero las diferencias entre ellas no son cuantificables. Ejemplos:
- Clasificación en un concurso (1º, 2º, 3º).
- Niveles de satisfacción (bajo, medio, alto).
Profundiza más
Este recurso te ayudará a visualizar de forma general sobre los diferentes tipos de variables en una base de datos. ¡Accede aquí!
Profundiza más
Este recurso te ayudará a visualizar los tipos de validación a las variables categóricas y numéricas. . ¡Accede aquí!
-
Hacer un envío
-
Hacer intentos: 1