Topic outline
-
Proyectos en la metodología cuantitativa
-
4. Proyectos en la metodología cuantitativa4.2. Uso de software de análisis de datos
Ilustración 1: Proyectos en la metodología cuantitativa - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Los proyectos en metodología cuantitativa buscan explorar fenómenos mediante la recolección y análisis de numéricos, para validar hipótesis o describir patrones. Este enfoque se caracteriza por su objetividad, replicabilidad y uso de herramientas estadísticas. Aunque son menos comunes en las ciencias sociales, es necesario comprender cómo se realizan metodológicamente, pues, su aporte, en la administración, permite procesar e interpretar correctamente las pruebas psicométricas. Por ello, no podemos perder de vista la importancia de esta metodología cuando las investigaciones se basan en instrumentos cuyo objetivo es ofrecer como resultado un dato numérico.
Por ejemplo, de acuerdo con las herramientas observadas en la clase anterior, en donde los instrumentos no solamente nos muestran datos numéricos, sino que elaboran perfiles y tendencias de acuerdo a un determinado patrón de respuestas.
4.1. Procedimientos y técnicas de análisis de datos cuantitativas
Los procedimientos y técnicas de análisis de datos cuantitativos consisten en una serie de procesos sistemáticos que tienen como propósito organizar, describir, interpretar y presentar los datos numéricos obtenidos en una investigación. Estos procedimientos garantizan que los datos recopilados sean analizados de manera rigurosa y permitan extraer conclusiones válidas y objetivas.
El principal objetivo de estas técnicas es comprender y explicar los patrones presentes en los datos, así como estudiar validar las hipótesis planteadas durante el desarrollo de la investigación. Esto se logra mediante el uso de herramientas estadísticas que permiten examinar tanto las características individuales de las como las relaciones entre ellas.
Hernández Sampieri y Mendoza (2018) mencionan que:
Al analizar los datos cuantitativos debemos recordar dos cuestiones: primero, que los modelos estadísticos son representaciones de la realidad, no la realidad misma; y segundo, los resultados numéricos siempre se interpretan en contexto, por ejemplo, un mismo valor de presión arterial no es igual en un bebé que en una persona de la tercera edad (p.310).
Entre las técnicas más utilizadas se encuentran:
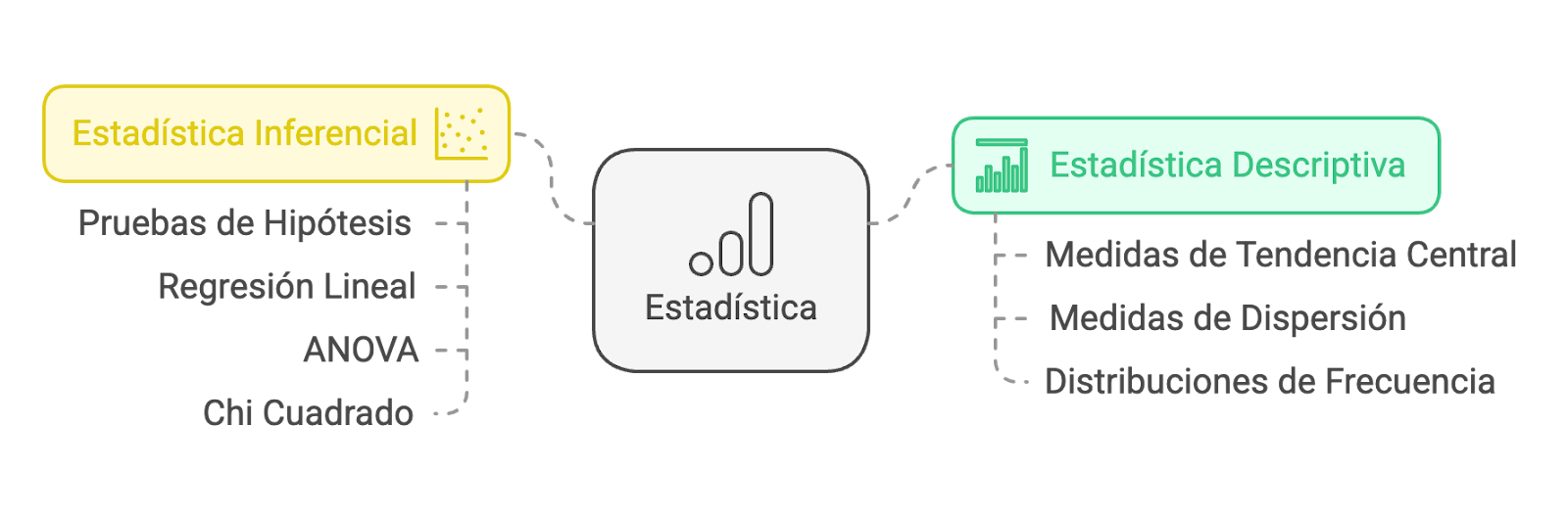
Ilustración 2: Técnicas estadísticas de procesamiento de datos - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) La estadística descriptiva: Se centra en resumir y representar los datos de manera clara y comprensible. Esto incluye el cálculo de medidas de tendencia central, como la media, la mediana y la moda, que permiten identificar valores representativos de un conjunto de datos. Asimismo, considera las medidas de dispersión, como la desviación estándar, la varianza y el rango, para evaluar la variabilidad de los datos, y distribuciones de frecuencia, que muestran cómo se distribuyen los valores de las variables en estudio. Para Masseroni, Domínguez y Libonatti (2016), “permite que los datos se presenten y organicen de manera tal que se pueda observar el comportamiento de la población en las variables consideradas, facilitando la interpretación de los resultados” (p. 25). Normalmente, la estadística descriptiva, tiene como función describir las características de la población estudiada.
Tipo Medida Explicación Fórmula Medidas de Tendencia Central Media (Promedio) Suma de todos los valores dividida entre el número total de observaciones. Indica el valor típico de la distribución. 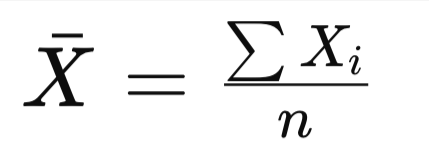
Mediana Valor central de un conjunto de datos ordenados. Divide la distribución en dos mitades iguales. Si n es impar: 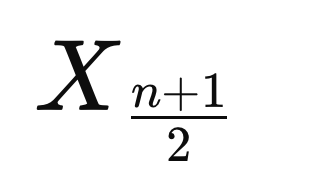
Si n es par: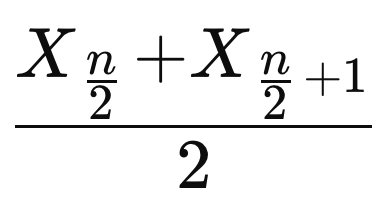
Moda Valor que más se repite en un conjunto de datos. Puede haber más de una moda o ninguna. Se determina observando la frecuencia de los datos. Medidas de Dispersión Rango Diferencia entre el valor máximo y el valor mínimo. Indica la amplitud de la distribución. R = Xmáx − Xmin Varianza Promedio de las desviaciones cuadráticas respecto a la media. Indica cuánta variabilidad hay en los datos. 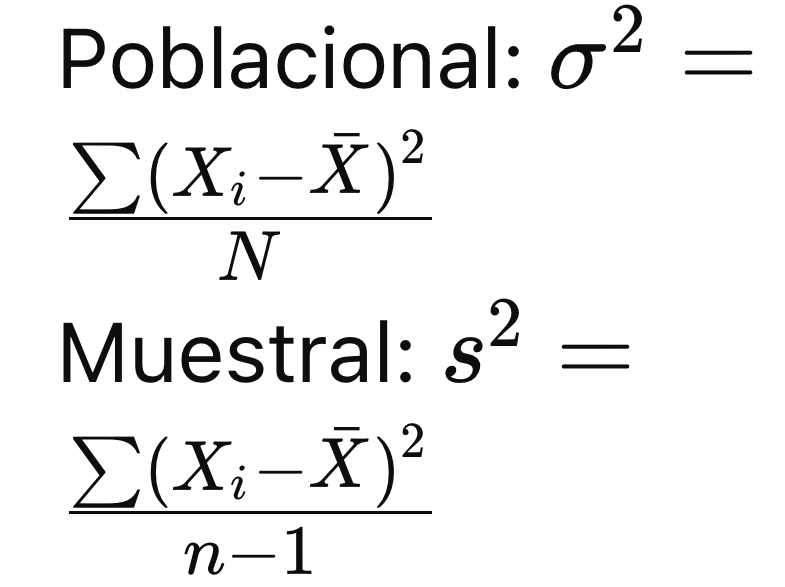
Desviación estándar Raíz cuadrada de la varianza. Expresa la dispersión de los datos en las mismas unidades que la variable original. Poblacional: 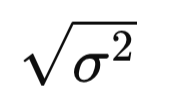
Muestral: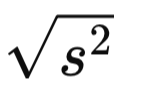
Coeficiente de variación Relación entre la desviación estándar y la media. Se expresa como un porcentaje y permite comparar dispersión entre conjuntos de datos con diferentes unidades. CV = (σ / x̄) × 100% Medidas de Posición Cuartiles Dividen los datos en cuatro partes iguales (Q1, Q2 y Q3). Q2 es la mediana. 
Percentiles Dividen los datos en 100 partes iguales. Se usan en evaluaciones y pruebas estandarizadas. Deciles Dividen los datos en 10 partes iguales. Medidas de Forma Asimetría (sesgo) Indica si la distribución está sesgada hacia la derecha (positiva), hacia la izquierda (negativa) o si es simétrica. Curtosis Mide el grado de concentración de los datos en la media. Puede ser mesocúrtica (normal), leptocúrtica (con colas largas) o platicúrtica (con colas cortas). 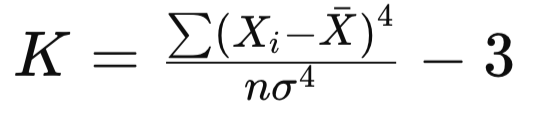
Tabla 1: Estadística descriptiva - Fuente: Cuadro elaborado por Diana Elizabeth Peñaloza Román. Información tomada de: IlustraciónProaño Rivera (2020) Media (Promedio)Tipo: Medidas de Tendencia Central
Explicación: Suma de todos los valores dividida entre el número total de observaciones. Indica el valor típico de la distribución.
MedianaTipo: Medidas de Tendencia Central
Explicación: Valor central de un conjunto de datos ordenados. Divide la distribución en dos mitades iguales.
Si n es impar:
Si n es par:
ModaTipo: Medidas de Tendencia Central
Explicación: Valor que más se repite en un conjunto de datos. Puede haber más de una moda o ninguna.
Fórmula: Se determina observando la frecuencia de los datos.
RangoTipo: Medidas de Dispersión
Explicación: Diferencia entre el valor máximo y el valor mínimo. Indica la amplitud de la distribución.
Fórmula: R = Xmáx − Xmin
VarianzaTipo: Medidas de Dispersión
Explicación: Promedio de las desviaciones cuadráticas respecto a la media. Indica cuánta variabilidad hay en los datos.
Poblacional:
Muestral:
Desviación estándarTipo: Medidas de Dispersión
Explicación: Raíz cuadrada de la varianza. Expresa la dispersión de los datos en las mismas unidades que la variable original.
Poblacional:
Muestral:
Coeficiente de variaciónTipo: Medidas de Dispersión
Explicación: Relación entre la desviación estándar y la media. Se expresa como un porcentaje y permite comparar dispersión entre conjuntos de datos con diferentes unidades.
Fórmula: CV = (σ / x̄) × 100%
CuartilesTipo: Medidas de Posición
Explicación: Dividen los datos en cuatro partes iguales (Q1, Q2 y Q3). Q2 es la mediana.
PercentilesTipo: Medidas de Posición
Explicación: Dividen los datos en 100 partes iguales. Se usan en evaluaciones y pruebas estandarizadas.
DecilesTipo: Medidas de Posición
Explicación: Dividen los datos en 10 partes iguales.
Asimetría (sesgo)Tipo: Medidas de Forma
Explicación: Indica si la distribución está sesgada hacia la derecha (positiva), hacia la izquierda (negativa) o si es simétrica.
CurtosisTipo: Medidas de Forma
Explicación: Mide el grado de concentración de los datos en la media. Puede ser mesocúrtica (normal), leptocúrtica (con colas largas) o platicúrtica (con colas cortas).
La estadística inferencial: Tiene como propósito analizar los datos de una muestra para realizar generalizaciones o inferencias sobre la población de interés. Estas técnicas incluyen pruebas de hipótesis, que ayudan a determinar si los patrones observados en los datos son estadísticamente significativos, estas pruebas pueden ser la regresión lineal, la t-student, el anova o el chi cuadrado.
Estas técnicas son esenciales para garantizar que el análisis de datos sea metódico y confiable, lo que contribuye a la validez de las conclusiones y la utilidad de los resultados en la toma de decisiones fundamentadas. Para Cortada de Kohan (1994), se trata de un conjunto de métodos que se fundamentan en la Teoría de la Probabilidad y que tienen por finalidad generalizar los resultados, obtenidos mediante una muestra, a toda una población.
4.1.1. Fases del análisis de datos cuantitativo:
El análisis de datos cuantitativos es un proceso organizado en varias etapas que permiten un tratamiento sistemático de la información obtenida durante la investigación. Estas fases permiten transformar los datos en información relevante para responder a los objetivos del estudio y a las hipótesis planteadas. A continuación, describimos las principales fases del análisis de datos cuantitativos, las que parten de las variables de investigación:
a. Preparación de los datos
La preparación de los datos es el primer paso para garantizar que la base de datos esté lista para ser analizada. Incluye:
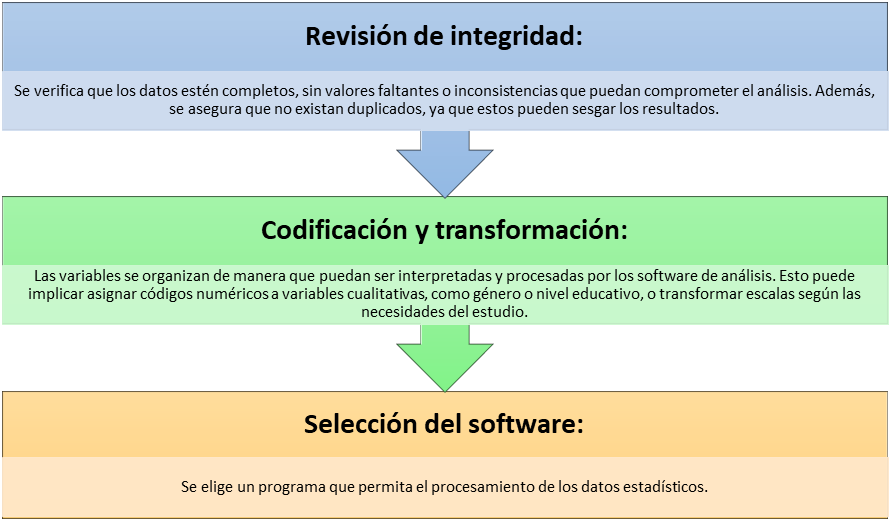
Ilustración 3: Preparación de los datos - Fuente: Cuadro elaborado por Diana Elizabeth Peñaloza Román. 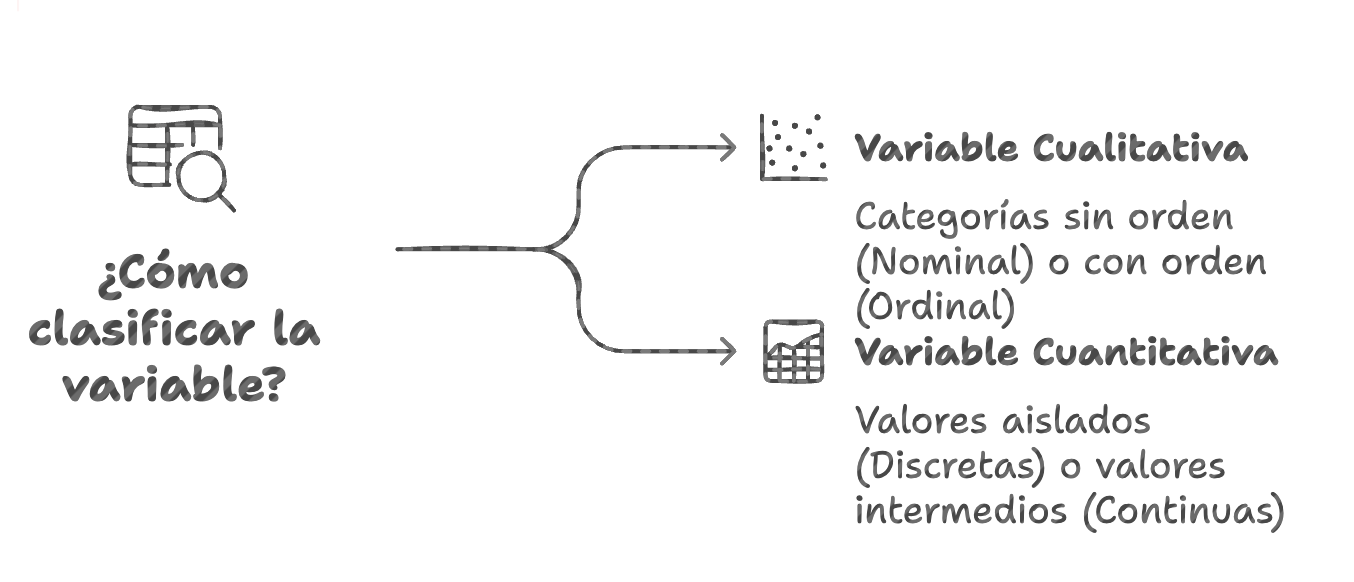
Ilustración 4: Variables cuantitativas y cualitativas - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) En esta etapa se clasifican las variables, según sean cualitativas -nominales (que nombran) u ordinales (que indican jerarquía)- o cuantitativas -discretas (números enteros) o continuas (números con decimales).
b. Limpieza o curación de la base de datos:
La limpieza es fundamental para garantizar la calidad de los datos y evitar errores en las conclusiones. Este proceso incluye:
Identificación y manejo de datos faltantes: Se decide cómo tratar los valores ausentes, ya sea mediante su eliminación, imputación (estimación de valores faltantes) o análisis separado.
Detección de valores atípicos: Se identifican datos que se desvían significativamente del patrón general y que pueden representar errores de medición, registros incorrectos o casos excepcionales que requieren análisis específico. Usualmente, los valores atípicos son borrados de la base de datos cargada en el programa de procesamiento estadístico.
Aprende más sobre la limpieza de las bases en esl siguiente apartado:
Aprende más
Para conocer más sobre Ideas necesarias para la limpieza de datos , puedes leer el siguiente artículo ¡Accede aquí!
c. Análisis descriptivo
El análisis descriptivo es la primera aproximación para comprender los datos recopilados. Su objetivo es resumir las características principales del conjunto de datos de manera clara y comprensible. Entre las técnicas utilizadas se incluyen:
Medidas estadísticas iniciales: Cálculo de indicadores estadísticos básicos como la media, la mediana, la moda (tendencia central), la desviación estándar y el rango (dispersión).
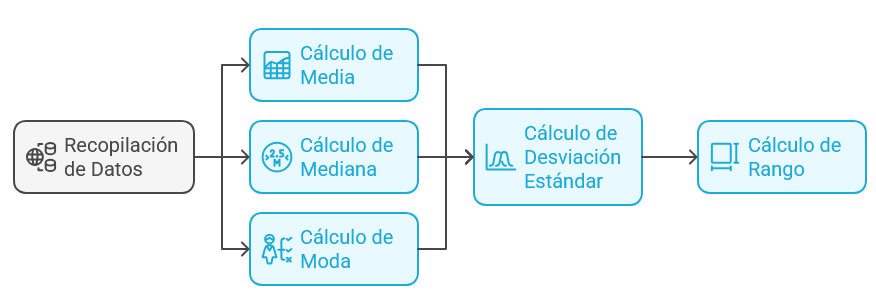
Ilustración 5: Procedimientos de estadística descriptiva -Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Tablas de frecuencias: Resumen de la cantidad de veces que ocurre cada categoría o rango de valores en las variables.
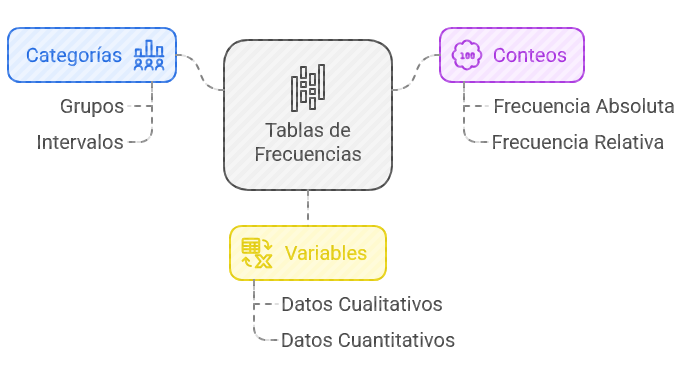
Ilustración 6: Tablas de frecuencias - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Gráficos: Representaciones visuales como histogramas, diagramas de dispersión o diagramas de caja que ayudan a identificar patrones y tendencias a partir de los datos obtenidos en las medidas estadísticas iniciales o en las tablas de frecuencias.
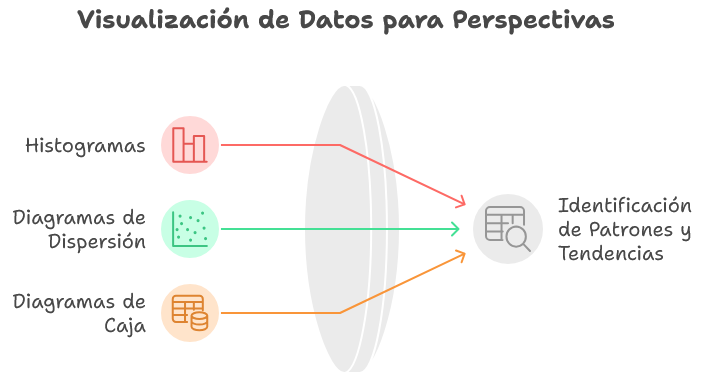
Ilustración 7: Gráficos - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) d. Análisis inferencial
El análisis inferencial permite ir más allá de la descripción para realizar generalizaciones sobre la población de estudio basándose en la muestra analizada, IlustraciónProaño Rivera (2020), menciona que es necesario que las características de la muestra sean claras para realizar estos procedimientos, si tienes dudas, revísalo en la clase anterior. Incluye la aplicación de pruebas estadísticas para comprobar hipótesis planteadas previamente. A estas pruebas estadísticas las llamamos pruebas de hipótesis y serán abordadas en el punto 5 de esta clase a profundidad.
Aprende más
A continuación encontrarás el detalle de lo que se trata una prueba de hipótesis. ¡Accede aquí!
e. Interpretación de resultados
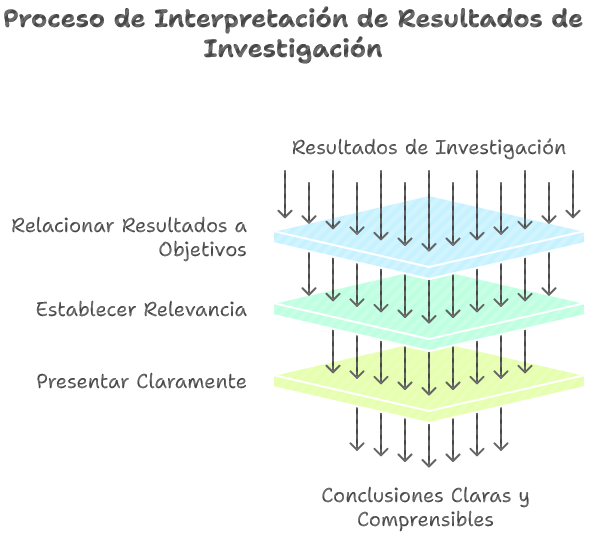
Ilustración 8: Proceso de interpretación de resultados - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) La última fase consiste en relacionar los resultados obtenidos con los objetivos del estudio para asegurar que, el análisis de datos cuantitativos sea un proceso metódico que respalde las conclusiones obtenidas en la investigación. Esto implica:
Describir y explicar cómo los resultados responden a las preguntas de investigación o responden a las hipótesis.
Establecer la relevancia e implicaciones de los resultados en el contexto del problema de investigación.
Presentar los resultados de manera clara, utilizando tablas, gráficos y textos interpretativos que permitan a los lectores comprender los hallazgos y su significado, considerando que se deben presentar los datos numéricos.
5. Pruebas de hipótesis más comunes en las ciencias socialesEl uso de software especializado en análisis de datos es una herramienta fundamental en la investigación, ya que facilita la organización, procesamiento y análisis estadístico de grandes cantidades de información de manera automatizada. Estos programas permiten obtener resultados precisos y reproducibles, optimizando el tiempo y reduciendo errores en el análisis manual.
Además, entre sus ventajas podemos observar que permiten:
- Procesar datos de manera eficiente, incluso en estudios con muestras muy grandes.
- Acelerar el análisis de datos y mejora su precisión
- Aplicar métodos estadísticos avanzados como regresión, análisis factorial y modelos de ecuaciones estructurales, pues son análisis complejos que serían muy difíciles de realizar manualmente.
- Visualizar los resultados mediante gráficos y tablas claras para interpretar hallazgos complejos.
Aprende más
Puedes aprender más sobre el procesamiento de datos en softwares especializados en el siguiente link ¡Accede aquí!
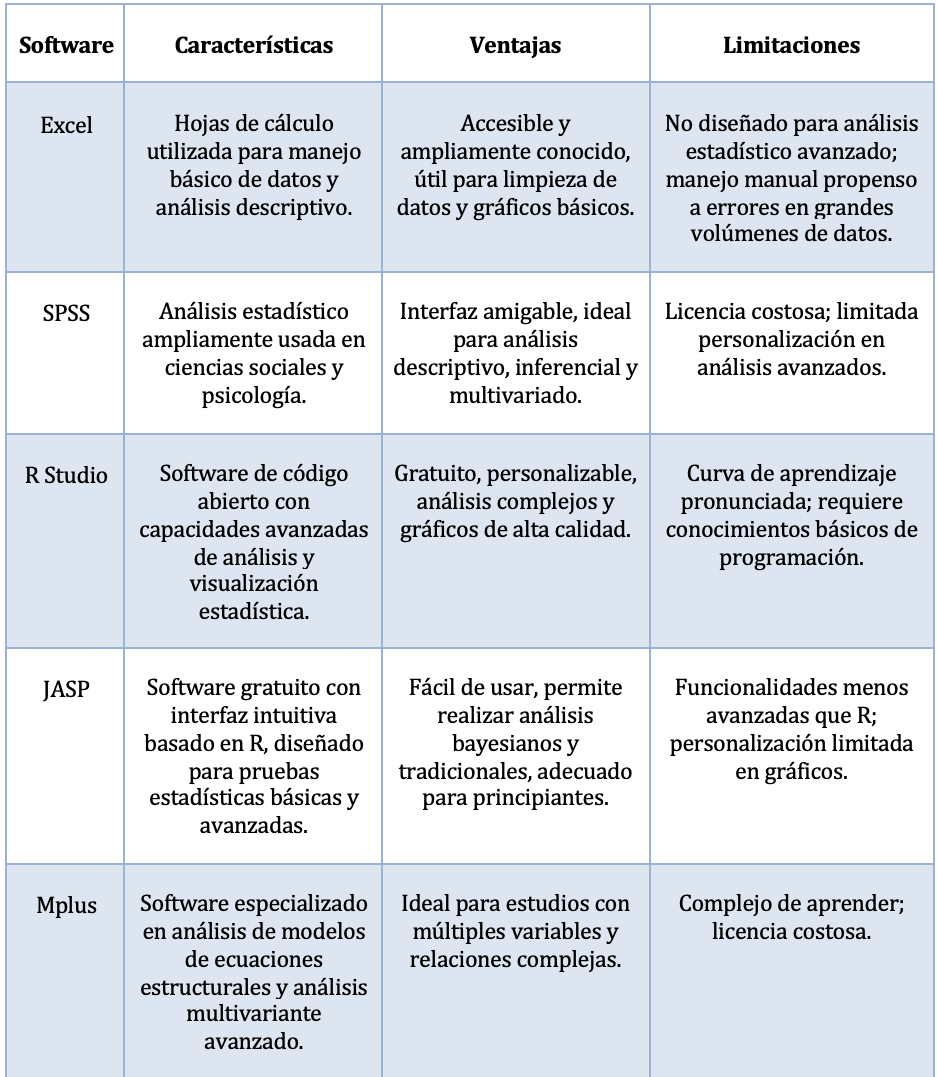
Tabla 2: Softwares de procesamiento de datos estadísticos - Fuente: Cuadro elaborado por Diana Elizabeth Peñaloza Román. 4.3. Limpieza de base de datos
La limpieza de la base de datos es un paso necesario en el análisis de datos, ya que asegura que la información sea precisa, confiable y adecuada para el procesamiento estadístico. Para Martínez Arias, Chacón Gómez y Castellanos López (2015), este proceso minimiza errores, elimina inconsistencias y permite que los resultados obtenidos sean representativos y válidos. En las investigaciones una base de datos “sucia” puede llevar a conclusiones erróneas, afectar la interpretación de resultados y llegar a conclusiones equivocadas.
Permite eliminar errores humanos y técnicos, como datos duplicados o valores mal ingresados, que pueden sesgar los análisis. Además, asegura la integridad de la base de datos, garantizando su coherencia con los objetivos del estudio y las preguntas de investigación. Este proceso mejora la calidad de los análisis al permitir la aplicación precisa de técnicas estadísticas avanzadas, evitando resultados engañosos que podrían distorsionar las métricas debido a valores atípicos o datos faltantes o perdidos.
¿Cómo se realiza?
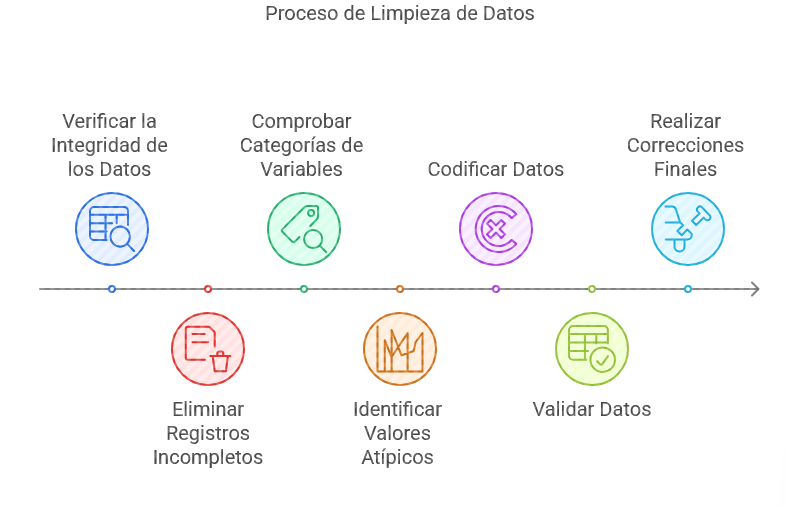
Ilustración 9: Fases de la limpieza de bases de datos - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) - -Verificar la integridad, para ello se revisa si los datos están completos y no existen valores duplicados o perdidos.
- -Eliminar los registros incompletos, cuando estos son mínimos.
- -Comprobar las categorías de las variables, observar que se hayan categorizado como ordinales, nominales, continuas o discretas.
- -Identificación y tratamiento de valores atípicos, que son aquellos que se alejan significativamente de la tendencia general de los datos. Estos valores se identifican a través de gráficos (caja y bigotes, histogramas) y de análisis de z-scores (valores superiores a ±3 suelen ser considerados atípicos).
- -Codificación, para reasignar valores para facilitar el análisis estadístico, por ejemplo, convertir respuestas de "sí/no" a "1/0" para realizar análisis estadísticos.
- -Validación de datos, se realizan tablas de frecuencia y estadística descriptiva para verificar patrones o inconsistencias.
- -Se hacen correcciones finales para hacer ajustes basados en el análisis preliminar.
5.2. Prueba T-Student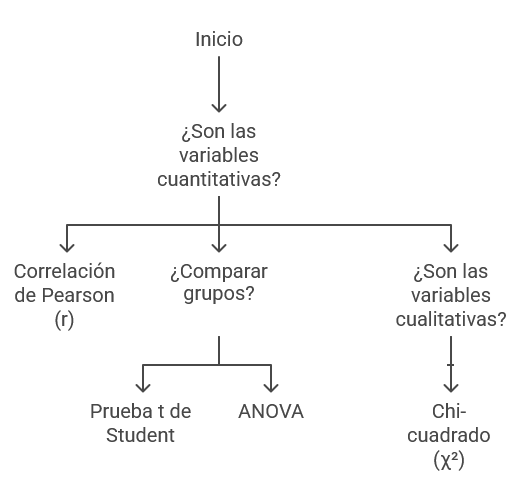
Ilustración 10: Pruebas de hipótesis - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Siguiendo a González Betanzos et al. (2017), las pruebas de hipótesis son una parte fundamental del análisis estadístico en las ciencias sociales. Estas pruebas nos permiten realizar inferencias y tomar decisiones basadas en los datos recolectados, determinando si hay suficiente evidencia para aceptar o rechazar una hipótesis planteada sobre una población.
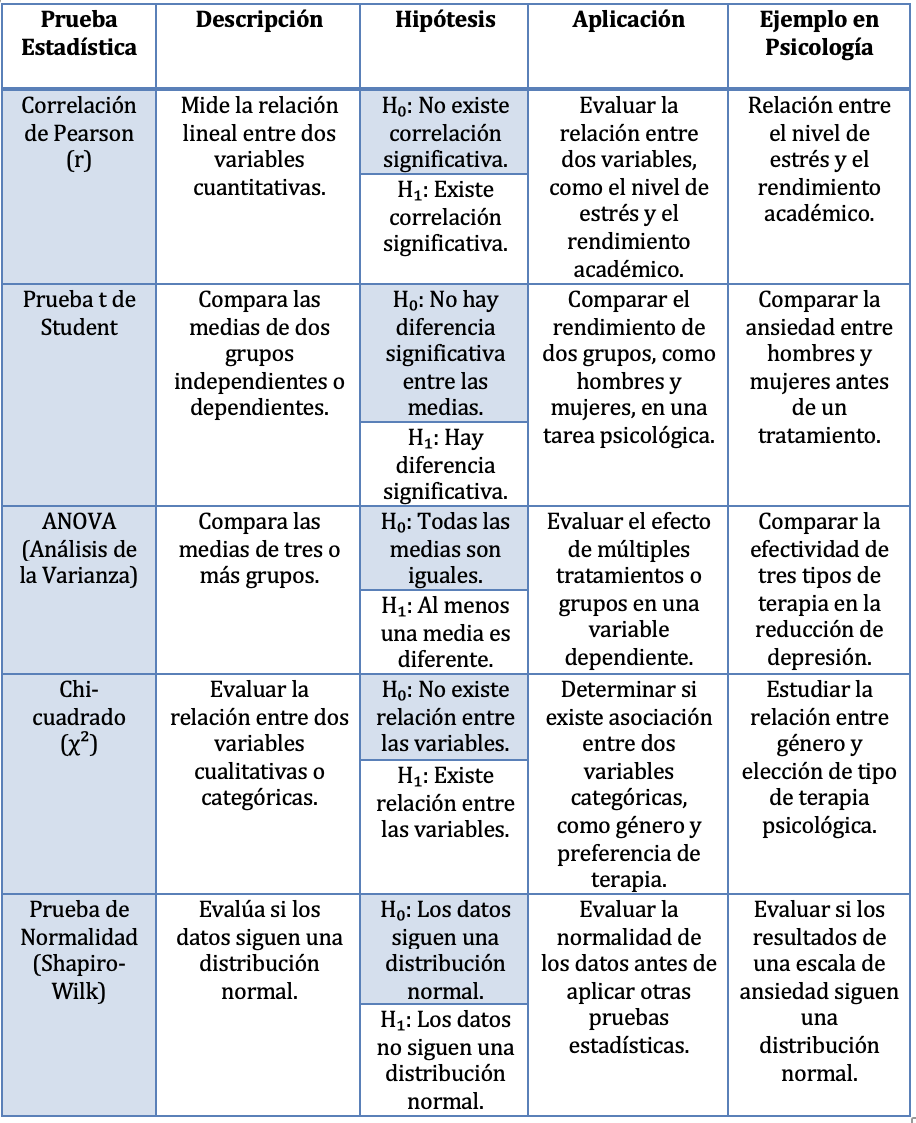
Tabla 3: Pruebas de hipótesis - Fuente: Cuadro elaborado por Diana Elizabeth Peñaloza Román. 5.1. Correlación de Pearson (r).
Cortada de Kohan (1994), menciona que la correlación de Pearson mide la relación lineal entre dos variables cuantitativas. Indica si las variables están asociadas de manera directa o inversa y con qué fuerza.
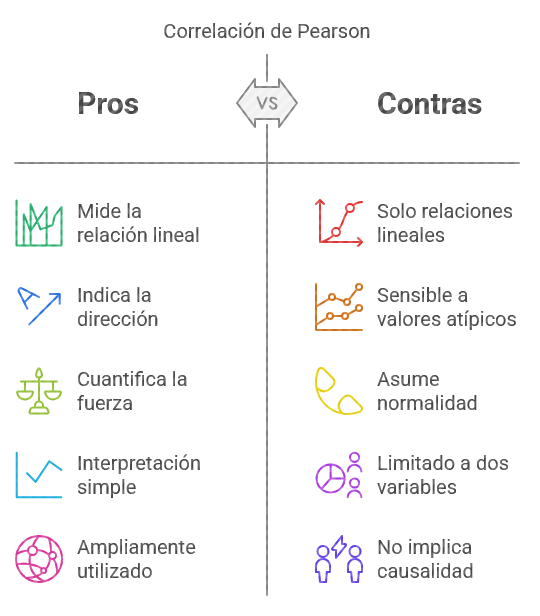
Ilustración 11: Correlación de Pearson - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Hipótesis:
Hipótesis nula (H₀): No existe correlación significativa entre las dos variables.
Hipótesis alternativa (H₁): Existe una correlación significativa entre las dos variables.
* En esta prueba, se espera que se rechace la hipótesis nula.
Interpretación:
Si el valor de r es cercano a 1 o -1, existe una fuerte relación lineal entre las variables (positivo o negativo, respectivamente).
Si el valor de r es cercano a 0, no hay relación lineal entre las variables.
Aprende más
Aprende más sobre la correlación de Pearson en la siguiente presentación ¡Accede aquí!
5.3. AnovaLa prueba t se utiliza para comparar las medias de dos grupos. Para Gonzales Betanzos et al., (2017), se usa cuando la muestra es pequeña (menos de 30) y se asume que los datos tienen distribución normal.
Aprende más
Revisa este artículo académico para aprender más a detalle de t-Student. Usos y abusos: ¡Accede aquí!
Hipótesis:
- Hipótesis nula (H₀): No hay diferencia significativa entre las medias de los dos grupos.
- Hipótesis alternativa (H₁): Hay una diferencia significativa entre las medias de los dos grupos.
* En esta prueba, se espera que se rechace la hipótesis nula.
Interpretación:
Si el valor p es menor que 0.05, se rechaza la hipótesis nula y se concluye que existe una diferencia significativa entre los grupos.
Tipos de prueba t:
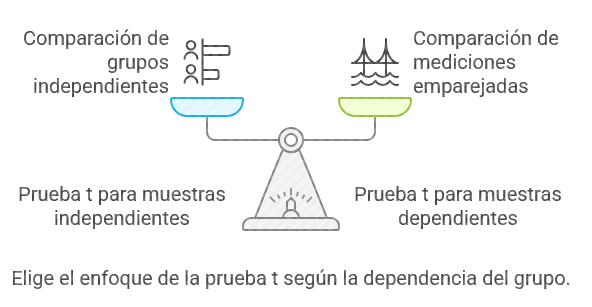
Ilustración 12: Tipos de prueba TFuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) - Prueba t para muestras independientes: Comparar dos grupos independientes, como, por ejemplo, hombres y mujeres.
- Prueba t para muestras dependientes: Comparar dos mediciones en el mismo grupo.
Hipótesis:
- Hipótesis nula (H₀): No hay diferencia significativa entre las medias de los dos grupos.
- Hipótesis alternativa (H₁): Hay una diferencia significativa entre las medias de los dos grupos.
* En esta prueba, se espera que se rechace la hipótesis nula.
Interpretación:
Si el valor p es menor que 0.05, se rechaza la hipótesis nula y se concluye que existe una diferencia significativa entre los grupos.
Aprende más
Para conocer más sobre Prueba “t”, puedes ver la siguiente infograía ¡Accede aquí!
5.2.1. Prueba de normalidad
La prueba de normalidad evalúa si los datos siguen una distribución normal, lo cual es un supuesto importante en muchas pruebas estadísticas como la prueba T. Según Álvarez Cáceres (2007), en la actualidad las pruebas más aplicadas para el ajuste de los datos a una distribución normal son la de Kolmogorov-Smirnov, si el tamaño de la muestra es mayor que 30 y la de Shapiro Wilks si el tamaño de la muestra es menor o igual que 30.
Para extrapolar los datos de la prueba t, es necesario que se realice la prueba de normalidad, esta prueba, determinará que la distribución de nuestra muestra no es atípica y que por lo tanto, estos datos son generalizables, por ello, a diferencia de las pruebas de hipótesis, en las pruebas de normalidad esperamos rechazar la hipótesis alternativa.
Pruebas comunes de normalidad
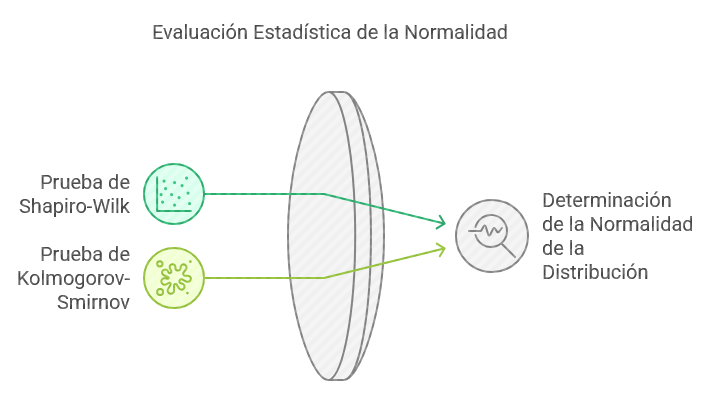
Ilustración 13: Pruebas comunes de normalidad - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) - Prueba de Shapiro-Wilk: Específicamente utilizada cuando el tamaño de la muestra es pequeño.
- Prueba de Kolmogorov-Smirnov: Compara la distribución de los datos con una distribución normal teórica.
Hipótesis:
- Hipótesis nula (H₀): Los datos siguen una distribución normal.
- Hipótesis alternativa (H₁): Los datos no siguen una distribución normal.
Interpretación:
Si el valor p es menor que 0.05, se rechaza la hipótesis nula, lo que sugiere que los datos no siguen una distribución normal.
5.4. Chi cuadrado (x2)ANOVA o análisis de varianza, para Dagnino (2014), es una técnica utilizada para comparar las medias de tres o más grupos o más de dos mediciones repetidas. Permite determinar si existen diferencias significativas entre las medias de diferentes grupos en una variable dependiente.
Hipótesis:
- Hipótesis nula (H₀): Todas las medias de los grupos son iguales.
- Hipótesis alternativa (H₁): Al menos una media de los grupos es diferente.
* En esta prueba, se espera que se rechace la hipótesis nula.
Tipos de ANOVA
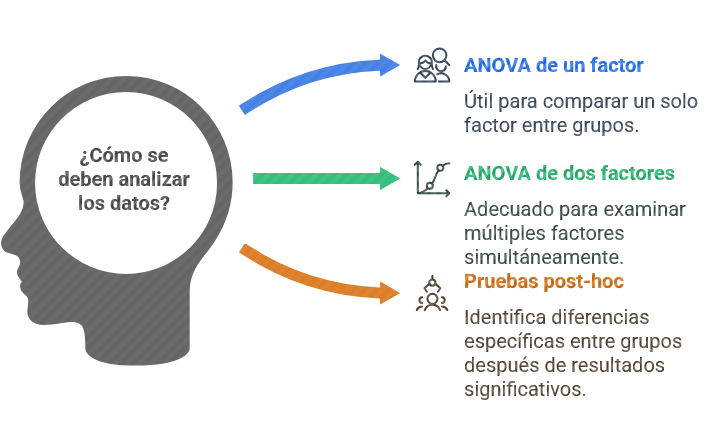
Ilustración 14: ANOVA - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) - ANOVA de un factor: Compara un solo factor.
- ANOVA de dos factores: Compara dos factores al mismo tiempo.
Interpretación:
Si el valor p es menor que 0.05, se rechaza la hipótesis nula y se concluye que hay diferencias significativas entre los grupos.
Si la prueba ANOVA muestra diferencias significativas, se suelen realizar pruebas post-hoc (como el método de Tukey) para identificar cuáles grupos son diferentes entre sí.
APRENDE MAS 5: Aprende más sobre el ANOVA en la siguiente presentación:
5.3.1. Prueba de homogeneidad
Álvarez Cáceres (2007), también menciona que la prueba de Levene es de amplio uso y su propósito es el de evaluar si las varianzas de dos o más grupos son iguales. Es importante porque muchas pruebas estadísticas, como la prueba t y ANOVA, asumen homogeneidad de varianzas. Usualmente, la prueba de Levene se usa en el ANOVA.
Del mismo modo en que ocurre con la prueba t, para extrapolar los datos del ANOVA, es necesario que se realice la prueba de homogeneidad, esta prueba, determinará que la distribución de nuestra muestra no es atípica, que los grupos tienen características parecidas y que por lo tanto, estos datos son generalizables, por ello, a diferencia de las pruebas de hipótesis, en las pruebas de homogeneidad esperamos rechazar la hipótesis alternativa.
Hipótesis:
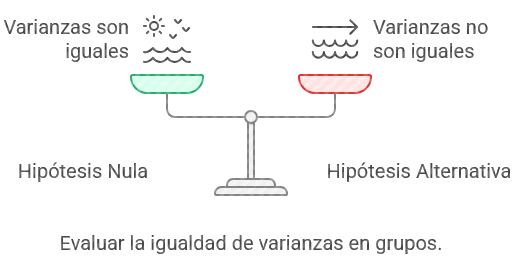
Ilustración 15: Prueba de homogeneidad - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) - Hipótesis nula (H₀): Las varianzas son iguales entre los grupos.
- Hipótesis alternativa (H₁): Las varianzas no son iguales entre los grupos.
Interpretación
Si el valor p es menor que 0.05, se rechaza la hipótesis nula y se concluye que las varianzas no son iguales, lo que puede requerir el uso de pruebas estadísticas alternativas5.3.2. Método de Tukey
Según la página de Minitab (22 de enero de 2025), el método de Tukey es una prueba estadística post-hoc que se utiliza después de realizar un ANOVA (Análisis de Varianza) para identificar qué grupos específicos presentan diferencias significativas entre sí. Su propósito es hacer comparaciones entre todas las posibles combinaciones de grupos, controlando el error de tipo I (falsos positivos) cuando se realizan múltiples comparaciones.
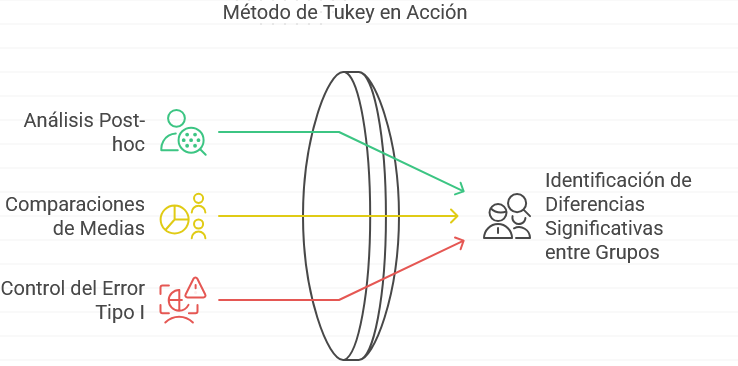
Ilustración 16: Método de Tukey - Fuente: Imagen elaborada con Napkin.IA. (19 de enero de 2025) Características principales:
- Post-hoc: Se aplica después de haber encontrado una diferencia significativa en el ANOVA. El ANOVA solo indica si existen diferencias generales entre los grupos, pero no especifica cuáles son esos grupos. El método de Tukey ayuda a resolver esa incertidumbre.
- Compara todas las medias posibles: El método realiza comparaciones entre todas las combinaciones posibles de medias de los grupos para determinar cuáles difieren significativamente.
- Controla el error tipo I: Cuando se realizan múltiples pruebas de comparación, aumenta la probabilidad de cometer errores tipo I (rechazar una hipótesis nula que es verdadera). El método de Tukey ajusta este riesgo al hacer comparaciones de manera más estricta.
La prueba de chi-cuadrado se utiliza para evaluar si existe una relación significativa entre dos variables cualitativas (categóricas). Esta prueba compara las frecuencias observadas con las frecuencias esperadas en una tabla de contingencia. Según Cortada de Kohan (1994), en la prueba de chi-cuadrado no necesitamos que los datos provengan de poblaciones o universos que se distribuyan normalmente.
Hipótesis:
- Hipótesis nula (H₀): No existe relación entre las dos variables.
- Hipótesis alternativa (H₁): Existe una relación significativa entre las dos variables.
Interpretación
Si el valor p es menor que 0.05, se rechaza la hipótesis nula y se concluye que las variables están asociadas.
Aprende más
Para conocer más sobre distribución libre, puedes leer el siguiente artículo ¡Accede aquí!
Aprende más
continuación, se te ofrecerán una serie de recursos para que aprendas el uso del programa JASP que sirve para el procesamiento de datos cuantitativos con una interfaz amigable e intuitiva. ¡Accede aquí!
-
C4C1 - Cuestionario Quiz