Topic outline
-
Ecosistema Spark
-
5.1. Spark SQL5.2. Spark Streaming
La Figura 1 muestra información sobre el ecosistema de Spark.

Figura 1. Ecosistema Spark.
Obtenida de: https://data-flair.training/blogs/apache-spark-ecosystem-components/En esta sección nos concentraremos en conseguir los siguientes objetivos:
- Procesar datos estructurados usando el módulo de Spark SQL.
- Explicar los numerosos beneficios de trabajar con Spark SQL.
Spark SQLes el componente de Spark que permite consultar datos estructurados y datos no estructurados usando un lenguaje de consulta común. Se puede conectar con múltiples fuentes de datos y brinda APIspara convertir el resultado de los querys a RDDs en programas de Python, Scala y Java.
Spark SQL brinda el mecanismo para que los usuarios de SQL puedan desarrollar querys en Spark. Adicionalmente, Spark SQL habilita herramientas de Business Intelligence para conectarse a Spark usando protocolos estándar, como JDBC y ODBC. Spark SQL también brinda APIs para convertir los query data en dataframes, para mantener datos distribuidos. Los dataframes son estructuras que están organizadas mediante columnas y lucen básicamente como si fueran tablas.
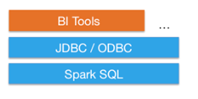
Figura 2. Standard Conectivity. Obtenida de: https://spark.apache.org/sql/ El primer paso para correr cualquier sentencia de SQL en Spark en crear el SQLContext. El segundo paso es crear un dataframe, con la finalidad de desarrollar operaciones complejas en el dataset. A continuación, se muestra un ejemplo del código que se debe usar. Ejemplo:
Código
from pyspark.sql import SQLContext sqlContext = SQLContext(sc)Los dataframes pueden ser creados por:
- RDDs creados con anterioridad.
- Tablas de hive o alguna otra fuente de datos.
Un archivo puede ser leído y convertido a un dataframe usando un único comando. La función show mostrará el dataframe en el Spark Shell. Ejemplo:
Código
# Leer df = sqlContext.read.json("/filename.json") # Mostrar df.show()Los RDDspueden ser convertidos en dataframes, pero requieren un poco más de trabajo. Primero hay que convertir cada línea a una fila y una vez que los datos están en un dataframe se puede realizar una serie de operaciones de transformación en él. Tal y como se muestra en la ilustración, pueden ser de tipo show, printSchema, select, filter y groupBy.
Código
#Leer from pyspark.sql import SQLContext, Row sqlContext = SQLContext(sc) # Cargar un archivo de texto y convertir cada línea en una fila. lines = sc.textFile("filename.txt") cols = lines.map(lambda l: l.split(",")) data = cols.map(lambda p: Row(name=p[0], zip=int(p[1]))) # Crear un dataframe df = sqlContext.createDataFrame(data) # Registrar el dataframe como tabla df.registerTempTable(”table") # Ejecutar el SQL Output = sqlContext.sql("SELECT * FROM table WHERE …") # Mostrar el contenido del dataframe df.show() # Imprimir el esquema df.printSchema() # Seleccionar solo la columna X df.select("X").show() # Seleccionar todos pero incrementar el descuento en un 5% df.select(df["name"], df["discount"] + 5).show() # Seleccionar la gente cuya altura sea superior a los 4.0 ft df.filter(df["height"] > 4.0).show() # Contar la cantidad de gente agrupada por zip df.groupBy("zip").count().show()En síntesis, Spark SQL permite ejecutar querys en spark, conectarse a una variedad de fuentes de datos y también deployar herramientas de business intelligence en Spark.
Documentación de Spark SQL [https://spark.apache.org/sql/]
5.3. Spark MLlibEn esta sección nos concentraremos en alcanzar los siguientes objetivos:
- Entender cómo funciona Spark datos en streaming.
- Listar algunas de las fuentes de datos en streaming que son soportadas por Spark.
- Describir la ventana de deslizamiento de spark (slidingwindows en Spark).
Spark Streaming brinda procesamiento escalable para datos en tiempo real, que corren en la parte superior de Spark Core.

Figura 3. Spark Streaming. Obtenido de: https://spark.apache.org/docs/latest/streaming-programming-guide.html Los datos continuos en streaming son convertidos o agrupados en RDDs discretos, que luego pueden ser procesados en paralelo. Spark streaming brinda APIs para Scala, Java y Python, así como otros productos de Spark. Spark Streaming puede leer datos desde varios tipos de fuentes, incluyendo Kafka y Flume. Apache Kafka es una plataforma de transmisión de datos en tiempo real, que permite recopilar, procesar y almacenar grandes volúmenes de información; mientras que Flume recolecta y aplica funciones de agregación sobre logs de datos.

Figura 4. Spark Streaming Data Sources. Obtenido de: https://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming también puede leer información desde fuentes de datos batch, tales como HDF, S3 y muchas otras bases de datos No SQL. Además, Spark Streming puede leer directamente de Twitter (X) y muchas más fuentes que proveen datos en tiempo real.
Creación y procesamiento en Spark Streaming:Spark Streming lee datos en streaming y los convierte en microbatches, que se los conoce como DStreams, que es el nombre corto para discretized stream o en español stream discreto. En el siguiente ejemplo, se puede ver un flujo de datos en streaming de 10 segundos, que es convertido en cinco RDDs usando una longitud de batch de dos segundos.
De manera similar que otros RDDs, transformaciones tales como map, reduce y filter pueden ser aplicadas a los DStreams. DStreams pueden ser agregados en ventanas que te permiten aplicar procesamiento y de datos. En este ejemplo, el tamaño de la ventana es de 4 segundos y el sliding interval es de 2 segundos.
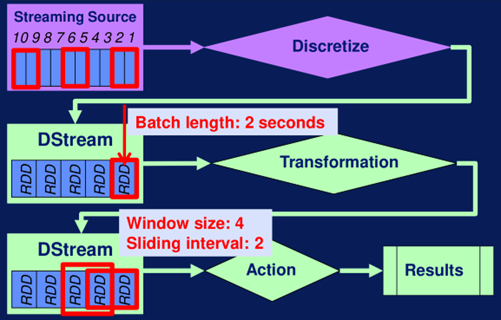
Figura 5. Procesamiento de datos con Spark Streaming: Coursera Big Data Integration and Processing Para concluir:
- Spark Streaming es una librería deSparkque permite trabajar con datos en streaming en un nearreal time.
- DStreams pueden ser usados como cualquier otro RDD; y pueden pasar por cualquier otra transformación, como un dataset batch.
- DStreams pueden crear una sliding window, para realizar cálculos en una ventana de tiempo.
Aprende más
Para conocer más sobre Documentación de Spark Streaming , puedes leer el siguiente artículo ¡Accede aquí!
5.4. Spark Graph XEl objetivo de esta sección es:
- Describir qué es y en qué consiste Mlib.
- Listar las categorías principales de las técnicas disponibles en Mlib.
- Explicar parte del código contenido en los algoritmos de Mlib.
Mlib es una librería escalable de machine learning que corre en la parte superior de Spark Core. Mlib brinda una implementación distribuida de los algoritmos de machine learning más comunes, así como algunas funciones utilitarias. Al igual que Spark Core, Mlib tiene APIs para Scala, Java, Python y R.

Figura 6. Spark Mlib. Obtenido de: https://spark.apache.org/mllib/ Mlib ofrece algunas técnicas y algoritmos comúnmente usados en un proceso de machine learning. Las principales categorías son: Machine Learning, Estadística y algunas herramientas utilitarias para técnicas comunes. Tal como el nombre lo sugiere, varios de los algoritmos de machine learning están disponibles en Mlib. Estos son algoritmos que se usan para construir modelos de clasificación, regresión y clustering.
También hay técnicas para evaluar el resultado de los modelos. Por ejemplo, se pueden computar los valores, para la curva ROC (Receiver of Creating Characteristics), que es una técnica estadística muy común para graficar el performance de un modelo de clasificación binaria.
Mlib también provee funciones estadísticas; por ejemplo, podemos nombrar estadísticas summary, promedios, desviación estándar, etc.; correlaciones y métodos para crear muestras sobre un dataset. Mlib también tiene técnicas comúnmente utilizadas en el proceso de machine learning, tales como reducción de dimensionalidad y métodos de transformación de features para preprocesamiento de datos. En pocas palabras, Spark Mlib ofrece algunas técnicas usadas frecuentemente en los pipelines de machine learning.
A continuación, se muestra el código en pyspark para relizar un summary statistics de columnas de un dataset de números:
Código
# Importamos la librería Statistics desde el módulo stat de mlib from pyspark.mllib.stat import Statistics # Creamos los datos en un RDD dataMatrix = sc.parallelize([ [1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12] ]) # Computamos las estadísticas de la columna summary = Statistics.colStats(dataMatrix) print(summary.mean()) print(summary.variance())A continuación, se muestra un ejemplo para crear un modelo de clasificación binaria usando un árbol de decisión.
Código
# Importamos las librerías from pyspark.mllib.tree import DecisionTree, DecisionTreeModel from pyspark.mllib.util import MLUtils # Leemos y parseamos los datos data = sc.textFile("data.txt") # Creamos el árbol de decisión para clasificación model = DecisionTree.trainClassifier (parsedData, numClasses=2) print(model.toDebugString()) model.save(sc, "decisionTreeModel")En este último ejemplo, se muestra el código para un modelo de clustering de tipo k medias.
Código
# Cargamos las librerías from pyspark.mllib.clustering import KMeans, KMeansModel from numpy import array # Leemos y parseamos los datos data = sc.textFile("data.txt") parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')])) # Definimos el modelo k means para clustering clusters = Kmeans.train (parsedData, k=3) print(clusters.centers)
En las próximas clases se hará mayor énfasis en algunos de los modelos de machine learning; por lo pronto, se brindan unos ejemplos de su implementación usando pyspark.
5.5. Explorar datos con Spark SQL y Spark DataFramesLos objetivos de esta sección son:
- Describir en qué consiste GraphX.
- Explicar cómo los vértices y las aristas son almacenados.
- Describir a alto nivel cómo funciona Pregel.
Graph X es una API de Apache Spark procesamiento en paralelo de grafos. Graph X usa su propio modelo de grafos. Esto significa que tanto los nodos como los vértices en un grafo pueden tener atributos y valores. En Graph X, las propiedades de los nodos son almacenados en una taba de vértices y las propiedades de los edges (aristas) son almacenados en una tabla de edges. La información de la conectividad, es decir, la información referente a la conexión entre aristas y nodos, se almacena de forma separada de las tablas que guardan las propiedades de las aristas y los nodos.

Figura 7. Spark GraphX. Obtenido de: https://spark.apache.org/graphx/ Graph X está creada a base de RDDs especiales para vértices y edges. VertexRDDrepresenta un conjunto de vértices, en donde todos ellos tienen un atributo llamado A. El EdgeRDD que se muestra en la siguiente ilustración extiende el almacenamiento básico de un edge para los edges que tienen un formato columnar en cada partición, para hacer más eficiente el performance. Nótese que VertexID solo puede tener un valor único por definición. La clase edge es un objeto con un vértice como fuente y un atributo edge como vértice destino.

Figura 8. EdgeRDD. Adicionalmente a la perspectiva de vértices y edges de las propiedades del grafo, Graph X también tiene triple view. La triple view joinea, lógicamente, las propiedades de los vértices y los edges. Graph X tiene un operador que puede ejecutar operaciones desde la librería Pregel para hacer analítica de grafos. Este operador Pregel ejecuta una serie de superpasos, que define un protocolo de mensajería para los vértices.

Figura 9. TripleView. Obtenida de: 
Para concluir, Spark puede ser usado también para procesamiento de grafos en paralelo mediante el uso e implementación de Graph X. El mismo que permite almacenar información relacionada con vértices y edges mediante el uso de RDDs especiales. Adicionalmente, el operador Pregel trabaja en una serie de superpasos.
Los objetivos de esta actividad son:
- Acceder a datos de archivos .csv con Spark SQL.
- Filtrar filas y columnas de los DataFrame de Spark.
- Agrupar y aplicar funciones de agregación en columnas de un DataFrame de Spark.
- Joinear dos DataFrames de Spark con base en una columna.
Paso 1:Conectar con los archivos.
Importamos el módulo de SparkSesion dado que es el entry point para empezar a trabajar con datos y dataframes.
Código
from pyspark.sql import SparkSessionLa segunda línea crea la sesión de Spark:
Código
spark = SparkSession.builder.appName("SQL").getOrCreate()Esta tercera línea sube el archivo csv gamecliks a hdfs desde un directorio local:
Código
hdfs dfs -copyFromLocal game-clicks.csv /users/bigdata/game-clicks.csvEsta línea de código crea un nuevo DataFrame de Spark en la variable df :
Código
df = spark.read.csv("hdfs:/users/bigdata/game-clicks.csv", header = True, inferSchema=True)
Paso 2: Ver el esquema del DataFrame y la cantidad de filas. Podemos llamar al método printSchema() para ver el esquema del DataFrame:
Código
df.printSchema()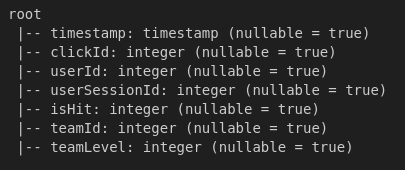
Lo que muestra este método es una lista con los nombres y los tipos de datos de cada una de las columnas del dataframe.
Llamamos al método count(), que cuenta la cantidad de filas del dataframe.
Código
df.count()755806
Paso 3. Vemos el contenido del dataframe. Podemos llamar al método show(). Para ver el contenido del dataframe. El argumento especifica la cantidad de filas a mostrar.
Código
df.show(5)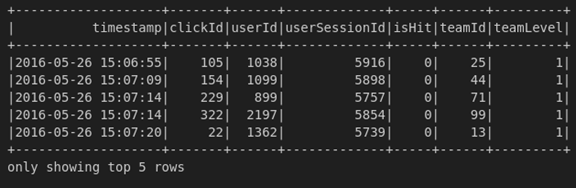
Paso 4. Filtrar columnas en un dataframe. Podemos filtrar por una o más columnas llamando al método select().
Código
df.select("userid", "teamlevel").show(5)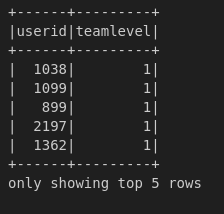
Paso 5. Filtrar filas con base en un criterio. También podemos filtrar en base a filas que coincidan con algún criterio específico usando el método filter()
Código
df.filter(df['teamlevel']>1).select('userid', 'teamlevel').show(5)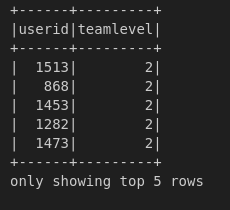
Los argumentos del método filter() son una columna, en este caso especificado como df[‘teamlevel’] y la condición, que en este caso es mayor a 1. El segundo método que se ejecuta es el método select(), que solo muestra las columnas userid y teamlevel y mediante el comando show mostramos únicamente los primeros cinco registros.
Paso 6. Agrupar por una columna y count. El método groupBy() agrupa los valores de columna(s). La columna ishit solo tiene dos valores 0 o 1. Podemos calcular la cantidad de ocurrencias agrupando la columna ishit y contando los resultados:
Código
df.groupBy('ishit').count().show()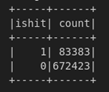
Paso 7. Calcular el promedio y la suma. Las funciones de agregación pueden ser ejecutadas sobre columnas de un dataframe. Primero, vamos a importa la librería que tiene las funciones de agregación. Luego vamos a calcular el promedio y el total de valores llamando a los métodos mean() y sum() respectivamente.
Código
from pyspark.sql.functions import mean, sum df.select(mean('ishit') , sum('ishit')).show()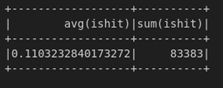
Paso 8. Joinear dos dataframes. Podemos realizar un merge o join de dos dataframes en base a una columna. Primero, vamos a crear el dataframe para los adclicks y vamos a guardar el resultado en la variable df2:
Código
df2 = spark.read.csv("hdfs:/users/bigdata/ad-clicks.csv", header = True, inferSchema=True)Vamos a ver las columnas del df2 llamando al método printSchema()
Código
df2.printSchema()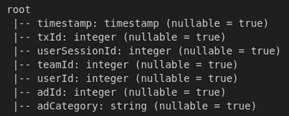
Podemos ver que el df2 también tiene columna userid. Luego, vamos a combinar el dataframe gameclicks y el addclicks llamando al método join() y guardamos el resultado en una variable llamada merge:
Código
merge = df.join(df2, 'userid')En la línea de código anterior estamos llamando al método join() sobre el dataframe gameclicks; el primer argumento es el dataframe a joinear; en este caso addClicks, y el segundo argumento es el nombre de la columna que está presente en ambos dataframes.
Ahora veremos el esquema del dataframe resultante:
Código
merge.printSchema()Podemos ver que el dataframe resultante tiene todas las columnas tanto de gameclicks como de adclicks.
Finalmente, vemos el contenido del dataframe merge:
Código
merge.show(5)
Profundiza más
Este recurso te ayudará a enfatizar sobre el tema ¡Accede aquí!