Diagrama de temas
-
PROC LENG NTRL EN LA EDUCACIÓN - P1155-TEÓRICO-N0082-01-N01
Miscelánea
-
Análisis de sentimiento
-
5.1. Fundamentos5.2. Pros y Contras
El análisis de sentimiento, también conocido como minería de opiniones (Jboback, 2025), es una disciplina del procesamiento del lenguaje natural (PLN) y la que se enfoca en identificar y extraer información subjetiva de textos. Su objetivo principal es determinar la polaridad de un documento, oración o fragmento de texto, clasificándolo como positivo, negativo o neutro. Esta técnica es esencial para comprender las actitudes, opiniones y emociones expresadas en diversas fuentes de datos textuales, como reseñas de productos, publicaciones en redes sociales y comentarios de clientes.
Enfoques
El análisis de sentimiento se basa en técnicas de PLN y aprendizaje automático para evaluar el tono emocional de un texto. Existen principalmente dos enfoques para llevar a cabo este análisis (Gupta, 2024):
- Enfoque basado en reglas: Este método utiliza diccionarios de palabras con anotaciones de polaridad (positiva o negativa) y reglas gramaticales para evaluar el sentimiento de un texto. Por ejemplo, palabras como "excelente" o "terrible" se asocian con sentimientos positivos o negativos, respectivamente. Sin embargo, este enfoque puede ser limitado al enfrentar expresiones sarcásticas o contextos complejos.
- Enfoque de aprendizaje automático: Este método implica entrenar modelos en grandes conjuntos de datos etiquetados para que aprendan a identificar patrones asociados con diferentes sentimientos. En este sentido, algoritmos como máquinas de soporte vectorial (SVM), redes neuronales y modelos de transformers, como BERT, se emplean para este propósito. Estos modelos pueden capturar matices más sutiles en el lenguaje y manejar mejor la ambigüedad y el contexto.
Tipos de Análisis de Sentimiento
Dependiendo del nivel de detalle y la especificidad requerida, el análisis de sentimiento se puede clasificar en varios tipos (Zhu, 2023):
- Análisis de Sentimiento de Grano Fino: Este tipo de análisis no solo clasifica el sentimiento como positivo, negativo o neutro, sino que también asigna una puntuación que indica la intensidad del sentimiento. Por ejemplo, una reseña de 5 estrellas se consideraría muy positiva, mientras que una de 1 estrella sería muy negativa (Figura 1).
Figura 1. Sentimientos positivos y negativos
Nota: Tomado de Velldal (2022) - Análisis basado en aspectos: En lugar de evaluar el sentimiento general de un texto, este enfoque se centra en identificar sentimientos asociados con aspectos específicos de un producto o servicio (Figura 2). Por ejemplo, en una reseña de un hotel, el análisis podría distinguir entre sentimientos sobre la limpieza, el servicio o la ubicación.
Figura 2. Sentimientos asociados a aspectos
Nota: Tomado de Intellica.AI (2020) - Detección de emociones: Más allá de la polaridad, este tipo de análisis busca identificar emociones específicas expresadas en el texto, como alegría, tristeza, ira o miedo. Esto proporciona una comprensión más profunda de las reacciones emocionales de los usuarios.

Figura 1. Sentimientos positivos y negativos 
Figura 2. Sentimientos asociados a aspectos Aplicaciones del análisis de sentimiento
El análisis de sentimiento tiene una amplia gama de aplicaciones en diversos campos:
- Monitoreo de redes sociales y reputación de marca: Las empresas utilizan el análisis de sentimiento para evaluar la percepción pública de su marca en tiempo real. Al analizar publicaciones en redes sociales, pueden identificar rápidamente comentarios negativos y abordar posibles crisis de reputación (Figura 3).

Figura 3. Monitoreo de Redes Sociales - Mejora de productos y servicios: Al analizar comentarios y reseñas de clientes, las organizaciones pueden identificar áreas de mejora en sus productos o servicios y adaptar sus estrategias en consecuencia.
- Análisis de opinión pública: En el ámbito político, el análisis de sentimiento se emplea para evaluar las opiniones de los ciudadanos sobre políticas, candidatos o eventos actuales, proporcionando información valiosa para la toma de decisiones (Figura 4).

Figura 4. La Opinión Pública Desafíos en el Análisis de Sentimiento
A pesar de sus avances, el análisis de sentimiento enfrenta varios desafíos:
- Detección de sarcasmo e ironía: Las expresiones sarcásticas pueden transmitir un sentimiento opuesto al significado literal de las palabras, lo que dificulta su correcta interpretación por parte de los algoritmos (Figura 5).
Figura 5. Sarcasmo e ironía
Nota: Tomado de Orenes (2014) - Ambigüedad lingüística: Muchas palabras o frases pueden tener significados diferentes según el contexto, lo que complica la determinación precisa del sentimiento (Figura 6).
Figura 6. Ambigüedad Lingüística
Nota: Tomado de UCLM (2021) - Variaciones culturales y lingüísticas: El análisis de sentimiento debe adaptarse a diferentes culturas y dialectos, ya que las expresiones emocionales pueden variar significativamente entre distintas poblaciones

Figura 5. Sarcasmo e ironía 
Figura 6. Ambigüedad Lingüística 
Figura 7. Variaciones Culturales y Dialectos 5.3. TécnicasEsta herramienta ha ganado relevancia en campos como el marketing, la atención al cliente y la gestión de la reputación en línea. Sin embargo, su aplicación conlleva tanto ventajas como desafíos que es crucial considerar (Dilmegani, 2024).
Pros del análisis de sentimiento
- Monitoreo de la Reputación de Marca: Permite a las empresas evaluar en tiempo real la percepción pública de su marca, productos o servicios. Al analizar comentarios en redes sociales, reseñas y otras fuentes, las organizaciones pueden identificar rápidamente tendencias negativas y abordar posibles crisis reputacionales.
- Mejora de Productos y Servicios: Al desglosar las opiniones de los clientes, las empresas pueden identificar áreas específicas de mejora en sus ofertas. Por ejemplo, si múltiples usuarios expresan insatisfacción con una característica particular de un producto, la empresa puede priorizar su optimización.
- Eficiencia en la Gestión de Grandes Volúmenes de Datos: Las herramientas automatizadas de análisis de sentimiento pueden procesar vastas cantidades de datos en poco tiempo, proporcionando insights valiosos sin la necesidad de una revisión manual exhaustiva.
Contras del análisis de sentimiento
- Dificultad para detectar sarcasmo e ironía: Las expresiones sarcásticas o irónicas pueden ser interpretadas incorrectamente por los algoritmos, ya que el significado literal difiere del sentimiento real. Por ejemplo, la frase "¡Qué genial, se rompió en mi primer uso!" podría ser clasificada erróneamente como positiva.
- Ambigüedad y contexto: Palabras o frases que son neutrales pueden adquirir connotaciones positivas o negativas según el contexto. Por ejemplo, describir un teléfono como "pequeño" puede ser percibido como positivo por su portabilidad o negativo por una pantalla reducida.
- Variaciones lingüísticas y culturales: El análisis de sentimiento debe adaptarse a diferentes dialectos, jergas y expresiones culturales. Una palabra o frase puede tener significados distintos en diferentes regiones, lo que complica la precisión del análisis.
- Precisión limitada en modelos automatizados: Aunque los enfoques basados en aprendizaje automático pueden manejar grandes volúmenes de datos, a menudo funcionan como una "caja negra", lo que dificulta la interpretación y corrección de errores sin reentrenar el modelo con nuevos datos.
5.4. HerramientasPara llevar a cabo este análisis, se emplean diversas técnicas que han evolucionado con el tiempo, desde enfoques basados en reglas hasta métodos avanzados de aprendizaje profundo.
Enfoques basados en reglas
Los métodos basados en reglas utilizan algoritmos que aplican reglas lingüísticas predefinidas para evaluar el lenguaje. Estas reglas pueden incluir la tokenización, lematización y el uso de léxicos que asignan polaridad a palabras específicas. Por ejemplo, palabras como "excelente" pueden ser etiquetadas como positivas, mientras que "terrible" como negativas. Aunque este enfoque es directo, requiere un esfuerzo considerable para crear y mantener las reglas, y puede carecer de flexibilidad para manejar contextos complejos o sarcasmo.
Enfoques de aprendizaje automático
Los métodos de aprendizaje automático (ML) automatizan el análisis de sentimiento al entrenar modelos en grandes conjuntos de datos etiquetados. Estos modelos aprenden a identificar patrones asociados con diferentes polaridades de sentimiento. Algoritmos como máquinas de soporte vectorial (SVM) y redes neuronales se emplean comúnmente en este enfoque. Por ejemplo, un modelo puede ser entrenado con reseñas de productos para predecir si una nueva reseña es positiva o negativa. Este enfoque es más adaptable que el basado en reglas, pero requiere grandes cantidades de datos etiquetados para un rendimiento óptimo.
Enfoques de aprendizaje profundo
El aprendizaje profundo ha revolucionado el análisis de sentimiento al permitir la captura de relaciones complejas en los datos. Modelos como BERT (Bidirectional Encoder Representations from Transformers) consideran el contexto completo de una palabra dentro de una oración, mejorando la precisión en la detección de sentimientos. Por ejemplo, BERT puede discernir el sentimiento en frases complejas o con ambigüedades contextuales que los modelos tradicionales podrían no captar.
Análisis basado en aspectos
El análisis de sentimiento basado en aspectos se enfoca en identificar sentimientos asociados con componentes específicos de un producto o servicio. Por ejemplo, en una reseña de un restaurante, el análisis podría distinguir entre opiniones sobre la comida, el servicio y la atmósfera, asignando sentimientos positivos o negativos a cada aspecto. Este enfoque proporciona una comprensión más detallada de las opiniones de los usuarios.
Técnicas de aumento de datos
Para abordar la escasez de datos etiquetados, especialmente en idiomas distintos al inglés, se emplean técnicas de aumento de datos (Luque, 2019). Una estrategia es la traducción bidireccional, donde un texto se traduce a otro idioma y luego se revierte al original, generando variaciones que enriquecen el conjunto de datos. Otra técnica es el "crossover" de instancias, que combina partes de diferentes textos para crear nuevos ejemplos. Estas técnicas ayudan a mejorar la robustez y generalización de los modelos de análisis de sentimiento.
6. Reconocimiento de entidades nombradas (NER)Para llevar a cabo el análisis de sentimiento de manera efectiva, existen diversas herramientas especializadas que emplean técnicas avanzadas de PLN e inteligencia artificial. A continuación, se presentan algunas de las herramientas más destacadas en este ámbito:
1. Brand24
Brand24 (Brand24, 2025) es una herramienta de monitoreo de medios que utiliza IA para detectar y analizar menciones en tiempo real en múltiples fuentes en línea. Ofrece un análisis avanzado de sentimientos, permitiendo a las marcas identificar y clasificar menciones como positivas, negativas o neutrales. Además, proporciona alertas de cambios significativos en el sentimiento, lo que facilita la gestión proactiva de la reputación en línea.
2. Repup monitoring tool
Repup (Repup, 2025) está diseñada para monitorear la reputación en línea de marcas personales o corporativas. A través de su función de "brand listening", permite analizar el sentimiento de las conversaciones sociales, ofreciendo métricas como la puntuación de sentimiento neto, tendencias a lo largo del tiempo y desglose por sentimiento negativo, positivo y neutral. También ofrece segmentación por países, género o idiomas, lo que facilita un análisis detallado y específico.
3. Hootsuite analytics
Hootsuite (Hootsuite, 2025) es una herramienta avanzada de análisis de sentimientos y monitoreo de redes sociales en tiempo real permite a las organizaciones comprender la percepción pública de su marca, productos y campañas. Ofrece capacidades para identificar posibles situaciones de crisis antes de que escalen, monitorear el éxito de campañas de marketing con datos en tiempo real y proteger la reputación abordando rápidamente los sentimientos negativos.
4. MeaningCloud
MeaningCloud (MeaningCloud, 2025) ofrece una API de análisis de sentimiento que realiza un análisis detallado y multilingüe de textos provenientes de diversas fuentes. Además de determinar la polaridad global de un texto, la API identifica la polaridad asociada a entidades y conceptos específicos dentro del mismo. También es capaz de detectar ironía y diferenciar entre opiniones y hechos objetivos, proporcionando un análisis más preciso y matizado.
5. MonkeyLearn
MonkeyLearn (MonkeyLearn, 2025) es una plataforma de análisis de texto que utiliza algoritmos avanzados de IA para evaluar las emociones y percepciones en reseñas de productos o servicios. Permite a las empresas extraer opiniones positivas o negativas más relevantes de tuits, publicaciones de Facebook o reseñas de productos, facilitando la comprensión de las opiniones de los clientes y la toma de decisiones informadas.
La selección de la herramienta adecuada para el análisis de sentimiento depende de las necesidades específicas de cada organización, el volumen de datos a analizar y el nivel de detalle requerido. Es esencial considerar factores como la precisión del análisis, la capacidad de manejar múltiples idiomas y la integración con otras plataformas utilizadas por la organización. Al elegir la herramienta más adecuada, las empresas pueden obtener insights valiosos que les permitan mejorar sus estrategias de comunicación y marketing, así como gestionar de manera efectiva su reputación en línea.
Profundiza más
Este recurso te ayudará a enfatizar sobre Análisis de sentimiento ¡Accede aquí!
6.2. Definición, Evaluación, Aproximación6.1. Fundamentos del NER
El Reconocimiento de Entidades Nombradas (NER) es una técnica esencial en el PLN que permite identificar y clasificar automáticamente entidades mencionadas en textos, como nombres de personas, organizaciones, ubicaciones y fechas (IBM, 2023). Su propósito es transformar datos textuales en información estructurada para su análisis y aplicación en diversas áreas (Figura 8).

Figura 8. NER El proceso de NER se divide en dos etapas: detección de entidades, que consiste en identificar fragmentos del texto que representan entidades, y clasificación de entidades, que asigna cada fragmento a una categoría específica. Existen tres enfoques principales para la implementación de sistemas de NER:
- Basados en reglas: Utilizan patrones y expresiones regulares para identificar entidades, pero su rigidez dificulta la adaptación a distintos contextos lingüísticos.
- Basados en aprendizaje automático: Emplean algoritmos supervisados como los Campos Aleatorios Condicionales (CRF), que aprenden patrones a partir de datos etiquetados.
- Basados en aprendizaje profundo: Modelos avanzados como BERT y Redes Neuronales Recurrentes (RNN) capturan relaciones contextuales complejas, mejorando la precisión en la identificación de entidades.
El NER tiene aplicaciones prácticas en múltiples sectores, incluyendo:
- Extracción de información, facilitando la identificación de entidades relevantes en grandes volúmenes de texto.
- Sistemas de respuesta a preguntas, ayudando a mejorar la precisión de asistentes virtuales y motores de búsqueda.
- Análisis de opinión, permitiendo evaluar percepciones sobre marcas, productos y figuras públicas.
6.3. DominioEl NER es una técnica del PLN que identifica y clasifica automáticamente entidades dentro de un texto, tales como nombres de personas, organizaciones, ubicaciones, fechas y valores numéricos. Su aplicación es clave en tareas como la extracción de información, el análisis de sentimientos y la recuperación de datos en grandes volúmenes textuales.
Definición del NER
El NER es un subtipo de la tarea de etiquetado secuencial, donde cada palabra de un texto es categorizada según su rol dentro de un conjunto predefinido de clases. Por ejemplo, en la frase "Amazon lanzó un nuevo servicio en Brasil", el sistema debería identificar Amazon como una organización y Brasil como una ubicación. Para lograrlo, los modelos pueden utilizar reglas basadas en diccionarios, algoritmos de aprendizaje automático o técnicas avanzadas de aprendizaje profundo, como Transformers.
Evaluación del NER
Para medir la efectividad de un modelo de NER, se utilizan métricas estándar de evaluación como:
- Precisión: Proporción de entidades correctamente identificadas entre todas las predicciones.
- Cobertura (Recall): Proporción de entidades detectadas correctamente en relación con todas las entidades existentes en el texto (Figura 9).
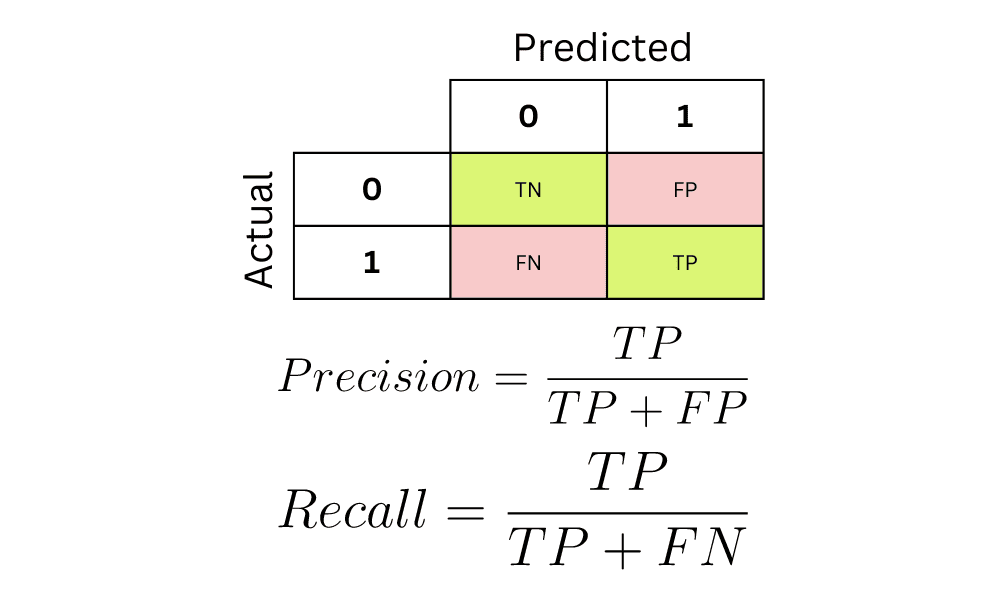
Figura 9. Precision and Recall - Puntaje F1: Promedio armónico entre precisión y cobertura, utilizado como métrica estándar en la evaluación de modelos de NER (Figura 10).
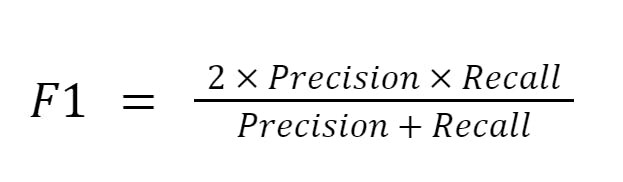
Figura 10. F1 Score La evaluación se realiza sobre conjuntos de datos etiquetados, como CoNLL-2003 o OntoNotes, que contienen anotaciones de entidades para comparar el rendimiento de diferentes enfoques.
Aproximación al NER
Existen tres principales estrategias para abordar el NER:
- Basado en Reglas y Diccionarios: Utiliza patrones predefinidos y listas de nombres propios para identificar entidades. Aunque efectivo en dominios específicos, su falta de flexibilidad limita su capacidad de generalización.
- Modelos de Aprendizaje Automático: Métodos como Máquinas de Soporte Vectorial (SVM) y Campos Aleatorios Condicionales (CRF) analizan patrones en los datos etiquetados para realizar predicciones.
- Enfoques de Aprendizaje Profundo: Modelos como BERT-NER y LSTM-CRF capturan el contexto semántico y mejoran la precisión, especialmente en textos complejos.
Profundiza más
Este recurso te ayudará a enfatizar sobre temática del NER ¡Accede aquí!
6.4. Introducción a OpenNLPEl término dominio en NER se refiere al contexto específico en el que se usa el modelo, como el ámbito financiero, biomédico, legal o de redes sociales (Pakhale, 2023). Cada dominio presenta desafíos únicos, ya que las entidades pueden tener significados distintos según el contexto. Por ejemplo, en el sector financiero, "Apple" puede referirse a una empresa, mientras que en un contexto general se interpretaría como una fruta.
El principal problema del dominio en NER es la transferencia de conocimiento. Modelos entrenados en corpus generales, como CoNLL-2003, suelen fallar en dominios específicos debido a la presencia de terminología especializada. En textos biomédicos, entidades como "BRCA1" (un gen relacionado con el cáncer) requieren modelos especializados, como BioBERT, que han sido ajustados con grandes cantidades de datos del sector salud.
Soluciones y Adaptación
Para mejorar la precisión del NER en dominios específicos, se han desarrollado diversas estrategias:
- Entrenamiento con datos específicos: Utilización de corpus especializados como BC5CDR para biomedicina o LegalNER para derecho.
- Modelos preentrenados y ajustados: Uso de técnicas como fine-tuning en modelos de lenguaje profundo, como SciBERT en textos científicos.
- Enriquecimiento con diccionarios y ontologías: Incorporación de bases de conocimiento para mejorar la identificación de entidades en nichos especializados.
El dominio juega un papel crucial en la efectividad del NER. Los modelos deben adaptarse a contextos específicos para mejorar la precisión y minimizar errores, garantizando así una extracción de información más precisa y relevante.
Apache OpenNLP (Apache OpenNLP, 2025) es una biblioteca de código abierto desarrollada en Java, utilizada en el PLN mediante algoritmos de aprendizaje automático. Su propósito es facilitar tareas como la detección de oraciones, tokenización, etiquetado gramatical (POS tagging), NER, lematización y análisis sintáctico.
Entre sus aplicaciones, destaca su uso en sistemas de análisis de opiniones, donde puede identificar entidades clave dentro de un texto. Por ejemplo, en la frase "Apple lanzó un nuevo iPhone en San Francisco", OpenNLP puede clasificar Apple como una organización, iPhone como un producto y San Francisco como una ubicación.
Gracias a su arquitectura modular, OpenNLP permite su integración en distintos sistemas de PLN, lo que facilita su personalización para diversas aplicaciones, desde asistentes virtuales hasta motores de búsqueda semántica. Su comunidad activa contribuye al desarrollo continuo de la herramienta, proporcionando soporte y mejoras constantes.
En este sentido, OpenNLP es una solución eficiente para el análisis automatizado de textos, con un enfoque flexible que permite abordar múltiples tareas dentro del PLN, siendo una herramienta esencial para investigadores y desarrolladores en el área del procesamiento de lenguaje natural.
-
Hacer intentos: 1