Diagrama de temas
-
PROC LENG NTRL EN LA EDUCACIÓN - P1155-TEÓRICO-N0082-01-N01
Miscelánea
-
9. Ingeniería de instrucciones
-
9. Ingeniería de instrucciones9.1. Aprendizaje en contexto
La ingeniería de instrucciones en el Procesamiento de Lenguaje Natural (PLN) es una disciplina que permite optimizar la forma en que los modelos de inteligencia artificial interpretan y generan texto. Se trata de un campo en constante evolución que busca mejorar la precisión y eficiencia de los modelos lingüísticos mediante el diseño de instrucciones precisas y adaptadas a diferentes tareas. En este contexto, el aprendizaje en contexto juega un papel clave, permitiendo a los modelos refinar sus respuestas en función de la información provista. Asimismo, existen diversas técnicas para transformar y generar texto, imagen y otros formatos no textuales, lo que expande las aplicaciones del PLN a diversas áreas del conocimiento. Esta clase explora en detalle estas dimensiones, proporcionando ejemplos específicos y analizando la aplicabilidad de cada enfoque.
Profundiza más
Este recurso te ayudará a enfatizar sobre Ingeniería de instrucciones ¡Accede aquí!
9.2. Técnicas texto a textoEl aprendizaje en contexto en PLN se refiere a la capacidad de los modelos de IA para generar respuestas adaptadas a una situación específica basándose en la información contextual que se les proporciona. Esto se logra a través de diversas estrategias, entre ellas el uso de few-shot learning y zero-shot learning (Kadam, 2020).
En el few-shot learning, el modelo recibe algunos ejemplos de una tarea determinada antes de realizar una predicción. Por ejemplo, si se le pide a un modelo de PLN generar resúmenes de artículos científicos, se le podrían proporcionar algunos ejemplos de resúmenes bien estructurados para que identifique patrones. Por otro lado, el zero-shot learning se basa en la capacidad del modelo para realizar tareas sin ejemplos previos, confiando en su preentrenamiento y en las instrucciones dadas.
Un aspecto clave del aprendizaje en contexto es la manipulación de los prompts o instrucciones para guiar al modelo hacia una salida deseada. Por ejemplo, en la generación de respuestas a preguntas en sistemas conversacionales, la especificidad de las instrucciones puede determinar la relevancia y utilidad de la respuesta. En aplicaciones médicas, un modelo puede ser instruido para diferenciar entre respuestas generales y diagnósticos específicos dependiendo del nivel de detalle en el prompt.
9.3. Técnicas Texto a ImagenLas técnicas de transformación texto a texto son herramientas utilizadas en PLN para modificar, reformular o mejorar textos a partir de algoritmos y modelos de inteligencia artificial. Estas técnicas incluyen la traducción automática, el resumen automático, la generación de texto y la conversión de texto a formato estructurado.
Un ejemplo destacado de esta técnica es la traducción automática, que ha avanzado significativamente con el desarrollo de modelos neuronales como Google Translate (Google, 2025) y DeepL (DeepL, 2025). Estos sistemas utilizan redes neuronales recurrentes y transformadores como GPT-4 (OpenAI, 2025a) y BERT (Devlin, 2019) para mejorar la precisión y fluidez de las traducciones en tiempo real (Figura 1).

Figura 1. Traducción texto a texto Otra aplicación clave es la generación automática de resúmenes, que permite sintetizar grandes volúmenes de información en textos más compactos sin perder el significado esencial. Herramientas como Sumy (miso-belica, 2025) y TextRank (Adamo, 2022) utilizan algoritmos de selección de oraciones clave basados en relevancia semántica y frecuencia de términos. Esto es particularmente útil en la investigación académica y el análisis de noticias, donde los profesionales requieren resúmenes precisos para una toma de decisiones eficiente (Figura 2).

Figura 2. Resumen texto a texto El parafraseo automático es otra técnica fundamental en texto a texto, utilizada para reformular frases manteniendo su significado original. Plataformas como QuillBot (Learneo, 2025) emplean inteligencia artificial para mejorar la redacción, facilitando la reescritura de contenido sin incurrir en plagio.

Figura 3. Parafraseo texto a texto La conversión de texto a formato estructurado es esencial en la extracción de información de documentos. Herramientas como SpaCy (Explosion, 2025) y NLTK (NLTK, 2024) permiten la identificación de entidades, relaciones semánticas y categorización de contenido, lo que optimiza procesos en minería de datos y análisis de información empresarial (Figura 4).
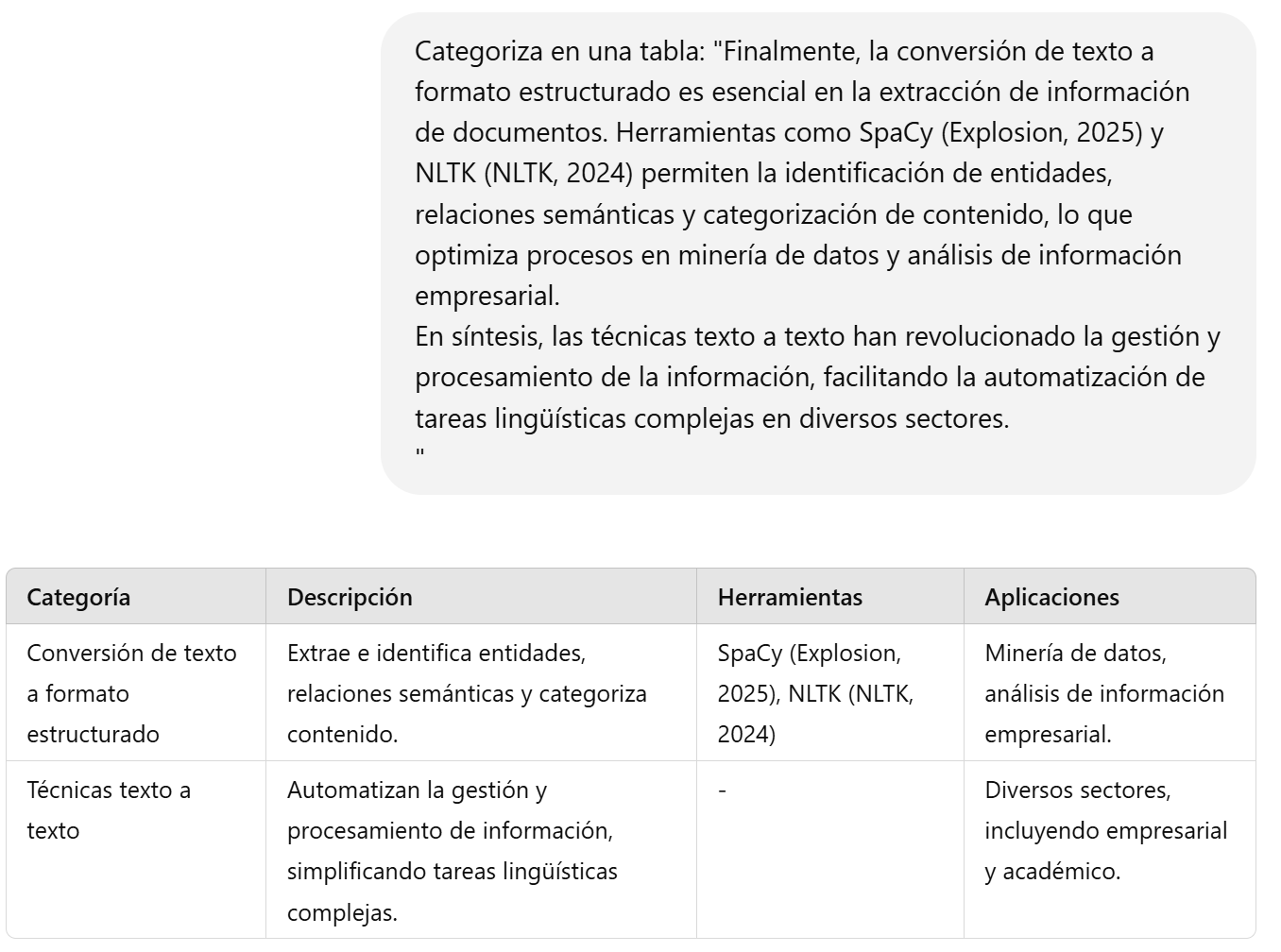
Figura 4. Categorización y estructuración texto a texto 9.4. Técnicas no textoLas técnicas de conversión de texto a imagen han avanzado con la integración de modelos de inteligencia artificial capaces de generar representaciones visuales a partir de descripciones textuales. Estas herramientas han encontrado aplicaciones en el arte digital, la publicidad, la medicina y la educación.
Uno de los avances más destacados en este campo es el uso de modelos generativos como DALL-E-3 (OpenAI, 2025b) y Stable Diffusion (StabilityAI, 2022), que permiten la creación de imágenes a partir de descripciones textuales (Figura 5). Estos modelos utilizan redes neuronales convolucionales y transformadores para interpretar instrucciones en lenguaje natural y generar ilustraciones detalladas.

Figura 5. Texto a Imagen En el ámbito publicitario, estas técnicas permiten la generación automática de contenido visual para campañas de marketing. Empresas como Adobe (Adobe, 2025) y Canva (Canva, 2025) han implementado herramientas que convierten descripciones en gráficos listos para su publicación, optimizando los tiempos de producción y personalización.
En medicina, la conversión de texto a imagen ha facilitado la visualización de datos clínicos complejos. Por ejemplo, en la radiología asistida por inteligencia artificial, los médicos pueden ingresar descripciones de síntomas y obtener representaciones visuales de posibles diagnósticos. Esto ha mejorado la precisión en la interpretación de imágenes médicas y la toma de decisiones.
Por otro lado, en la educación, las técnicas de texto a imagen han permitido la creación de contenido didáctico interactivo. Herramientas como ThingLink (ThingLink, 2025) y Genially (Genially, 2025) transforman conceptos textuales en diagramas y presentaciones visuales, mejorando la comprensión de temas complejos.
10. Uso de Transformer ModelsLas técnicas no texto incluyen métodos de comunicación y procesamiento de información que no dependen del lenguaje escrito. Estas abarcan desde la interpretación de señales visuales y auditivas hasta el análisis de patrones en datos sensoriales.
Un ejemplo clave de estas técnicas es el reconocimiento de imágenes y videos mediante inteligencia artificial (Figura 6). Algoritmos de visión computacional como los utilizados en sistemas de seguridad pueden identificar rostros, objetos y comportamientos en tiempo real, aplicándose en vigilancia, control de acceso y análisis de datos urbanos.
Figura 6. Descripción de imagen “no texto” En el ámbito de la salud, la tecnología de reconocimiento de voz ha revolucionado la transcripción médica y la interacción con dispositivos. Sistemas como Dragon Medical (Nuance, 2025) permiten a los médicos dictar informes clínicos sin necesidad de escribir, mejorando la eficiencia y reduciendo errores en la documentación.
Otro avance significativo es el análisis de señales cerebrales mediante (BCI, por sus siglas en inglés). Estas tecnologías han permitido la comunicación de personas con discapacidades severas mediante el control de dispositivos a través de ondas cerebrales, facilitando su autonomía e integración social (Figura 7).
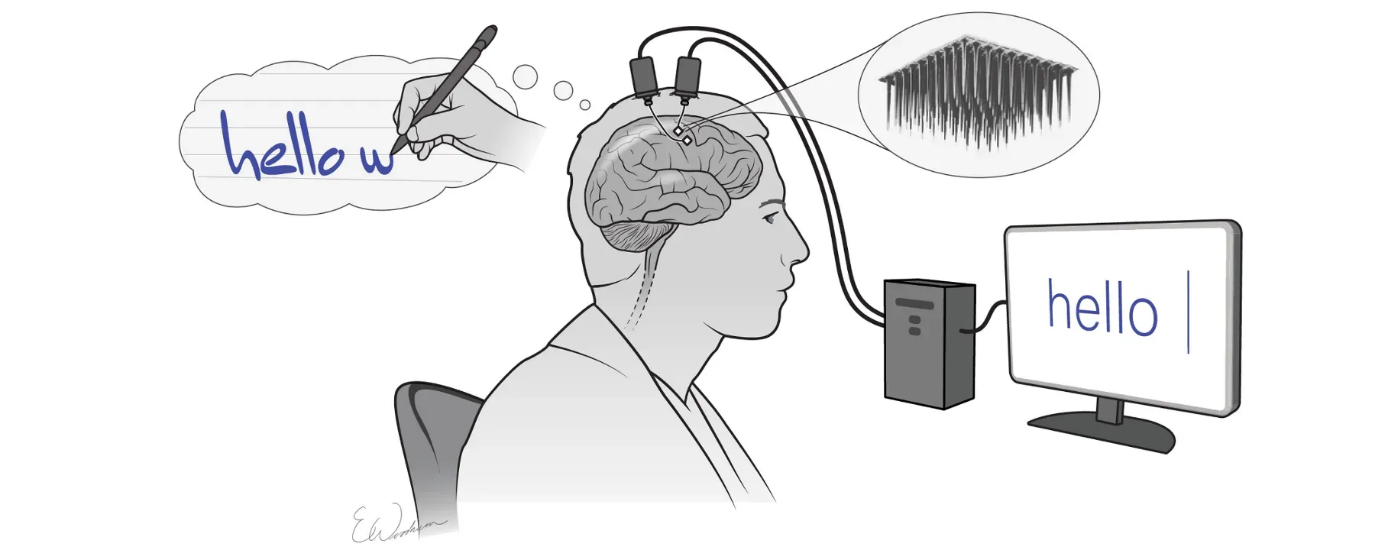
Figura 7. Brain Computer Interface En el entretenimiento, las técnicas no texto han impulsado la personalización de experiencias a través de la música y los videojuegos. Algoritmos de recomendación como los utilizados por Spotify y Netflix analizan patrones de consumo y preferencias del usuario sin necesidad de interacción textual, ofreciendo contenido adaptado a sus intereses.
10.1. Fundamentos técnicosEl PLN ha experimentado avances significativos en los últimos años, impulsados en gran parte por la introducción de los modelos Transformer. Estos modelos, que incluyen arquitecturas como BERT, GPT y T5, han revolucionado la forma en que las máquinas comprenden, generan y manipulan el lenguaje humano. A diferencia de los enfoques tradicionales basados en redes recurrentes (RNN) o convolucionales (CNN), los Transformers utilizan mecanismos de autoatención para procesar texto en paralelo, lo que mejora su eficiencia y capacidad de capturar relaciones contextuales de largo alcance.
La aplicación de los modelos Transformer en PLN abarca desde la traducción automática y la generación de texto hasta la respuesta a preguntas y el análisis semántico. Gracias a su flexibilidad y escalabilidad, estos modelos han sido adoptados en diversas áreas, incluyendo la educación, la atención al cliente y la investigación científica. Esta sección explora los fundamentos técnicos de los modelos Transformer, sus avances más recientes, sus aplicaciones en el ámbito educativo y su proyección futura, destacando sus implicaciones y desafíos.
10.2. Avances en modelos de lenguajeEl PLN ha experimentado una evolución significativa con el desarrollo de los modelos Transformer. Estos modelos han revolucionado la comprensión y generación de lenguaje natural al emplear mecanismos de autoatención que eliminan la dependencia de arquitecturas secuenciales como las redes neuronales recurrentes (RNN) y las redes convolucionales (CNN).
10.1.1. Principios de los modelos Transformer
La arquitectura Transformer se basa en el mecanismo de autoatención escalada (Self-Attention Mechanism), que permite al modelo evaluar la importancia relativa de cada palabra en una secuencia con respecto a las demás (Raschka, 2023). Esto se logra mediante el uso de tres componentes fundamentales:
- Vectores de consulta (Query)
- Vectores de clave (Key)
- Vectores de valor (Value)
Cada palabra en una oración se representa a través de estos vectores (Figura 8) y se procesa en paralelo, mejorando la eficiencia computacional y permitiendo la captura de dependencias a largo plazo en los textos.
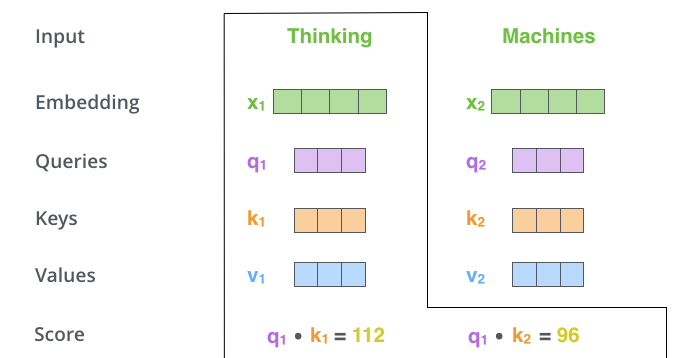
Figura 8. QKV vectors Además, los modelos Transformer incorporan un mecanismo de atención multi-cabezal (Multi-Head Attention), que permite a la red aprender múltiples representaciones de las relaciones semánticas de las palabras dentro del texto. Estos modelos también incluyen capas feedforward completamente conectadas y normalización por lotes (Batch Normalization) para mejorar la estabilidad del entrenamiento.
10.1.2. Principales modelos basados en Transformer
Desde la introducción del Transformer, han surgido diversas variantes optimizadas para distintas tareas de PLN. Algunos de los más destacados incluyen:
- BERT (Bidirectional Encoder Representations from Transformers): Introducido por Google, este modelo es entrenado con el método de enmascaramiento de palabras (Masked Language Model), permitiendo un aprendizaje bidireccional del contexto de las palabras en una oración. Se ha utilizado para tareas como la clasificación de texto, la extracción de información y la respuesta a preguntas.
- GPT (Generative Pre-trained Transformer): Desarrollado por OpenAI, este modelo es un Transformer unidireccional basado en aprendizaje auto-regresivo. Ha sido utilizado para tareas de generación de texto, chatbots y escritura creativa.
- T5 (Text-to-Text Transfer Transformer): Propuesto por Google, este modelo reformula todas las tareas de PLN en problemas de transformación de texto a texto, mejorando la versatilidad en tareas de traducción, resúmen automático y generación de texto.
10.1.3. Ejemplos de aplicación en PLN
- Traducción automática: Modelos como MarianNMT, basados en Transformer, han mejorado la precisión en la traducción de textos al captar mejor las relaciones semánticas y contextuales entre los idiomas.
- Generación de texto: Chatbots avanzados, como ChatGPT, emplean Transformers para producir respuestas coherentes y naturales en conversaciones humanas.
- Análisis de sentimientos: Modelos como RoBERTa se utilizan en plataformas de redes sociales y servicio al cliente para evaluar la opinión de los usuarios.
Los modelos Transformer han redefinido el PLN, mejorando la eficiencia y la precisión de las tareas de procesamiento del lenguaje. Con el continuo desarrollo de arquitecturas más especializadas y eficientes, su impacto en la inteligencia artificial y en la interacción humano-máquina seguirá expandiéndose en los próximos años.
10.3. Aplicaciones en la educaciónEl PLN ha experimentado una transformación radical con la aparición de los modelos de lenguaje basados en la arquitectura Transformer. Desde su introducción, estos modelos han superado significativamente a las aproximaciones anteriores basadas en redes neuronales recurrentes (RNN) y redes convolucionales (CNN). Gracias a su capacidad para procesar texto en paralelo y capturar dependencias de largo alcance, los modelos Transformer han impulsado el desarrollo de aplicaciones avanzadas en PLN.
10.2.1. Principales avances en los Modelos Transformer
Uno de los avances más significativos en los modelos Transformer ha sido la mejora en la eficiencia computacional y la adaptabilidad a distintas tareas de PLN. A continuación, se destacan algunos de los desarrollos más relevantes:
- BERT (Bidirectional Encoder Representations from Transformers)
- Introducido por Devlin en 2019, BERT revolucionó el PLN al utilizar un método de entrenamiento bidireccional, permitiendo que el modelo comprenda el contexto de una palabra basada en las palabras anteriores y posteriores en una oración.
- Aplicaciones: Respuesta a preguntas, clasificación de texto y análisis semántico.
- GPT (Generative Pre-trained Transformer)
- Desarrollado por OpenAI, GPT introdujo el preentrenamiento seguido de ajuste fino (fine-tuning) para tareas específicas. Su evolución ha llevado a versiones como GPT-2 y GPT-3, que han mejorado la coherencia y fluidez de la generación de texto.
- Aplicaciones: Chatbots, generación de contenido y asistencia en redacción automatizada.
- T5 (Text-to-Text Transfer Transformer)
- Propuesto por Google Research, T5 (Raffel, 2023) plantea un enfoque unificado en el que todas las tareas de PLN se reformulan como problemas de transformación de texto a texto.
- Aplicaciones: Traducción automática, generación de resúmenes y reformulación de textos.
- XLNet y RoBERTa
- XLNet (Yang, 2020) mejoró a BERT introduciendo una permutación de palabras para capturar mejor las relaciones contextuales.
- RoBERTa (Liu, 2019) optimizó el preentrenamiento de BERT aumentando la cantidad de datos y eliminando la predicción de la siguiente oración.
- Aplicaciones: Análisis de sentimientos, detección de entidades nombradas y motores de recomendación.
10.2.2. Ejemplos de Aplicación en PLN
Los avances en los modelos Transformer han permitido el desarrollo de aplicaciones prácticas con impacto en diversos sectores:
- Asistentes virtuales y chatbots: Modelos como ChatGPT han mejorado la interacción humano-máquina (Figura 9) proporcionando respuestas más precisas y contextualmente adecuadas.
- Traducción automática: Modelos como MarianMT han elevado la calidad de la traducción al capturar matices lingüísticos y culturales.
- Análisis de sentimientos y moderación de contenido: Empresas utilizan RoBERTa y BERT para detectar discursos de odio y mejorar la seguridad en plataformas digitales.
Figura 9. ChatGPT usado como Chatbot Los avances en los modelos de lenguaje basados en Transformer han revolucionado el PLN, abriendo nuevas oportunidades para la automatización y comprensión del lenguaje humano. Con el desarrollo de modelos más eficientes y especializados, el impacto de estas tecnologías continuará expandiéndose en los próximos años.
10.4. ProyecciónEl desarrollo de los modelos de lenguaje basados en la arquitectura Transformer ha revolucionado el PLN en diversas áreas, incluyendo la educación. Estos modelos, como BERT, GPT y T5, han mejorado significativamente la capacidad de las máquinas para comprender y generar texto, lo que ha permitido la creación de herramientas avanzadas para la enseñanza y el aprendizaje. Su aplicabilidad en la educación abarca desde asistentes virtuales hasta la automatización de la retroalimentación en evaluaciones, transformando la interacción entre estudiantes y sistemas de aprendizaje digital.
10.3.1. Personalización del Aprendizaje
Uno de los principales beneficios de los modelos Transformer en la educación es la personalización del aprendizaje. Los sistemas educativos basados en PLN pueden analizar el rendimiento y las respuestas de los estudiantes para adaptar el contenido de enseñanza a sus necesidades específicas. Modelos como GPT-4 pueden generar explicaciones personalizadas, resolver dudas en tiempo real y proporcionar ejemplos relevantes según el nivel de comprensión del estudiante.
Profundiza más
Este recurso te ayudará a enfatizar sobre Personalización del Aprendizaje ¡Accede aquí!
Ejemplo: En plataformas de e-learning como Coursera o Duolingo, los chatbots potenciados por Transformers pueden ajustar la dificultad de las preguntas y sugerir recursos adicionales basándose en el historial de respuestas del usuario.
10.3.2. Generación Automática de Contenidos Educativos
Los modelos de lenguaje pueden generar materiales de aprendizaje como resúmenes, preguntas de opción múltiple y explicaciones detalladas de conceptos complejos. T5, por ejemplo, puede transformar una explicación técnica en una versión más accesible para diferentes niveles educativos.
Ejemplo: Un profesor puede utilizar un modelo Transformer para generar automáticamente ejercicios de comprensión lectora a partir de un texto dado, reduciendo el tiempo dedicado a la elaboración manual de materiales.
10.3.3. Asistentes Virtuales para el Aprendizaje
Los asistentes virtuales potenciados por PLN pueden proporcionar tutorías en tiempo real, guiando a los estudiantes en la resolución de problemas matemáticos, redacción de ensayos o comprensión de textos complejos. Herramientas como ChatGPT pueden actuar como tutores personalizados que responden preguntas de manera inmediata y estructurada.
Ejemplo: Universidades han integrado chatbots en sus plataformas de aprendizaje para responder preguntas frecuentes sobre inscripciones, fechas de exámenes y requisitos académicos, aliviando la carga administrativa de los docentes.
10.3.4. Evaluación Automática y Retroalimentación Personalizada
Los modelos Transformer pueden mejorar la evaluación del rendimiento estudiantil mediante la corrección automática de textos, la detección de plagio y la generación de retroalimentación detallada. Modelos como RoBERTa y BERT pueden analizar respuestas escritas y proporcionar sugerencias de mejora basadas en criterios específicos.
Ejemplo: En cursos de escritura académica, una IA basada en Transformers puede evaluar la coherencia, gramática y estructura de los ensayos, ofreciendo comentarios en tiempo real sobre posibles mejoras en la argumentación.
Los modelos Transformer han abierto nuevas posibilidades en la educación, permitiendo una mayor personalización, eficiencia en la generación de contenido, automatización de evaluaciones y asistencia virtual avanzada. A medida que estos modelos continúan evolucionando, su integración en sistemas educativos promete mejorar la calidad del aprendizaje y optimizar la labor docente, facilitando una educación más accesible y efectiva.
El futuro de los modelos Transformer en PLN apunta a una mayor eficiencia y especialización. La investigación en modelos multimodales, como CLIP y DALL-E, está ampliando la aplicabilidad de estos modelos a tareas que combinan texto, imagen y audio. Además, el desarrollo de modelos más eficientes en términos computacionales, como los Transformers y compactos (Figura 10), busca reducir el alto costo de entrenamiento e inferencia.
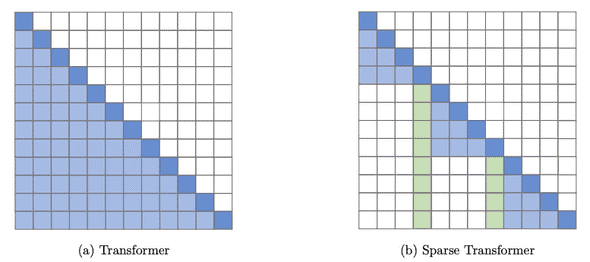
Figura 10. Transformer sparse vs. Compacto Otro campo emergente es el de los modelos adaptativos, capaces de ajustarse dinámicamente a distintos contextos sin necesidad de un reentrenamiento extenso. Esto permitirá aplicaciones más personalizadas en educación, salud y atención al cliente. A medida que la interpretabilidad de estos modelos mejora, también se abren oportunidades para su regulación y uso ético.
-
Hacer intentos: 1