Diagrama de temas
-
Aprendizaje supervisado segunda parte
-
6.1 Naïve Bayes6.2 Random Forest
Naïve Bayes Classifier es un algoritmo simple, de la familia de los clasificadores basados en probabilidad. Se llama ‘Naïve’ (ingenuo) porque asume que, dada una clase, los features son condicionalmente independientes. En otras palabras: Naïve Bayes Classifier asume que para todas las instancias de una determinada clase, los features no tienen correlación entre ellos. Entre algunas de sus características principales podemos citar:
- Altamente eficientes en cuanto a capacidad de aprendizaje y predicción se refiere.
- Su capacidad de generalización tiende a ser baja, en comparación con algoritmos de aprendizaje más sofisticados.
- Pueden ser muy buenos para determinadas tareas.
Tipos de Naïve Bayes:El Naïve Bayes Classifier es un algoritmo de clasificación basado en el teorema de Bayes, que asume independencia condicional entre las características del conjunto de datos. Existen tres variantes principales de este clasificador: Bernoulli Naïve Bayes, Multinomial Naïve Bayes y Gaussian Naïve Bayes, cada una diseñada para distintos tipos de datos y aplicaciones (Manning, Raghavan & Schütze, 2008).
El Bernoulli Naïve Bayes se emplea en datos binarios, donde cada característica puede tomar valores de 0 o 1. Es comúnmente utilizado en clasificación de texto con modelos de presencia/ausencia de palabras, como en el filtrado de spam (McCallum & Nigam, 1998). En contraste, el Multinomial Naïve Bayes maneja datos discretos y cuenta la frecuencia de ocurrencia de palabras en documentos, siendo ampliamente aplicado en problemas de minería de texto y categorización de documentos (Rennie, Shih, Teevan & Karger, 2003). Finalmente, el Gaussian Naïve Bayes es adecuado para datos continuos, asumiendo que las características siguen una distribución normal. Es usado en reconocimiento de patrones y detección de anomalías (Murphy, 2012).
Decision boundary (frontera de decisión) en el clasificador Gaussian Naïve Bayes es la curva o superficie que separa las regiones del espacio de características en función de la probabilidad de pertenencia a cada clase, asumiendo que las características siguen una distribución normal dentro de cada clase (Murphy, 2012). A continuación, la Figura 1 muestra cómo sería la decision boundary para un problema tipo de clasificación.
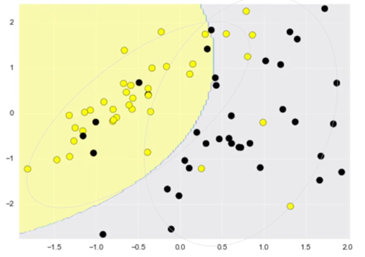
Figura 1. Decision Boundary – Gaussian Naïve Bayes Classifier. Ventajas y desventajas de usar Naïve Bayes Classifier
Ventajas Desventajas Fácil de entender Asumir que todos los features son condicionalmente independientes; dada una clase determinada, no es algo realista Estimación de parámetros fácil y eficiente Otros clasificadores usualmente tienen mejor poder de generalización Trabaja bien con datos que tienen alta dimensionalidad Su confianza estimada para las predicciones no es muy alta Usualmente se usa como baseline para compararlo con modelos más sofisticados Tabla: Ventajas y desventajas del clasificador Naive Bayes VentajaFácil de entenderDesventajaAsumir que todos los features son condicionalmente independientes; dada una clase determinada, no es algo realistaVentajaEstimación de parámetros fácil y eficienteDesventajaOtros clasificadores usualmente tienen mejor poder de generalizaciónVentajaTrabaja bien con datos que tienen alta dimensionalidadDesventajaSu confianza estimada para las predicciones no es muy altaVentajaUsualmente se usa como baseline para compararlo con modelos más sofisticados6.3 Redes neuronalesRandom Forest no es un solo árbol de decisión, es un ensamble de árboles decisión. Adicionalmente, es ampliamente usado y tiende a tener excelentes resultados en la resolución de múltiples problemas.
Scikit–learn tiene una implementación específica para este tipo de algoritmos y se encuentra en el módulo sklearn.ensemble:
- Clasificación: RandomForestClassifier
- Regresión: RandomForestRegressor
Un solo árbol de decisión tiende a caer en overfitting, mientras que el uso combinado de varios árboles de decisión tiende a generar modelos más estables, con una mejor generalización. La clave en este algoritmo es la diversidad de árboles de decisión individuales que lo componen. Los ensambles de árboles deberían ser diversos e introducir una variación aleatoria en la construcción de cada uno. El proceso de generación del Random Forest se explica de la siguiente manera:
El proceso de selección de los datos de entrenamiento para cada uno de los árboles se hace de forma aleatoria, este proceso se conoce como bootstrap sampling. Del mismo modo, los features que se usarán en cada uno de los árboles se seleccionan de forma aleatoria también. Lo primero que se hace para construir un Random Forest es escoger la cantidad de árboles de decisión que tendrá, eso se define con el parámetro n_estimator, que se aplica tanto para problemas de regresión como para los de clasificación. Luego, el parámetro max_features define la cantidad de features que se consideran en cada uno de los árboles de decisión.
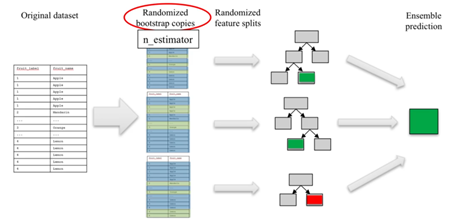
Figura 2. Random Forest Process. El proceso de aprendizaje del Random Forest es sensible al valor que tenga el parámetro max_features. Un valor de max_features de 1 tendería a crear árboles diversos y, en consecuencia, más complejos. Por otro lado, con un valor de max_features cercano a la cantidad total de features se obtendrán árboles más simples.
Predicciones usando Random Forest- Se hace una predicción para cada uno de los árboles del Random Forest.
- Las predicciones de los árboles se combinan de la siguiente manera:
- Para un modelo de regresión: se toma el promedio de las predicciones individuales
- Para un modelo de clasificación:
- Cada árbol genera una probabilidad para cada clase.
- Se saca el promedio de las probabilidades de todos los árboles.
- La predicción será la clase con la probabilidad más alta.
La Figura 3 ilustra el proceso descrito en el párrafo anterior.
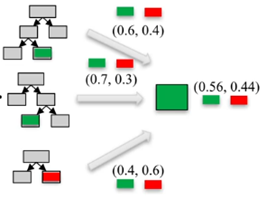
Figura 3. Predicciones usando Random Forest.
Ventajas y Desventajas de usar Random ForestVentajas Desventajas Altamente usado, muy buen performance en muchos problemas Los resultados suelen ser difíciles de interpretar para los humanos. No necesita normalización de datos o un extensivo tuneo de parámetros. Al igual que los árboles de decisión, el Random Forest podría no ser una buena alternativa para problemas con alta dimensionalidad. Al igual que en los árboles de decisión, maneja una gran cantidad de tipos de datos. Fácilmente paralelizable usando múltiples CPU. Tabla 2: Ventajas y Desventajas del Random Forest Ventajas- Altamente usado, muy buen performance en muchos problemas
- No necesita normalización de datos o un extensivo tuneo de parámetros.
- Al igual que en los árboles de decisión, maneja una gran cantidad de tipos de datos.
- Fácilmente paralelizable usando múltiples CPU.
Desventajas- Los resultados suelen ser difíciles de interpretar para los humanos.
- Al igual que los árboles de decisión, el Random Forest podría no ser una buena alternativa para problemas con alta dimensionalidad.
Parámetros esenciales para el RandomForestClassifier- n_estimator: número de árboles a usar en el ensamble.
- max_features: tiene un gran efecto en el performance.
- max_depth: controla la profundidad de cada árbol.
- n_jobs: cantidad de cores en paralelo durante el proceso de entrenamiento.
6.4 Data leakageLas redes neuronales artificiales (ANN, por sus siglas en inglés) son modelos computacionales inspirados en el funcionamiento del cerebro humano y están diseñadas para reconocer patrones complejos en los datos (Goodfellow, Bengio, & Courville, 2016). Se utilizan ampliamente en problemas de clasificación, regresión y reconocimiento de imágenes, entre otros (LeCun, Bengio, & Hinton, 2015).
Arquitectura de las redes neuronalesUna red neuronal está compuesta por neuronas artificiales, organizadas en tres tipos de capas:
- Capa de entrada: recibe los datos de entrada.
- Capas ocultas: procesan la información aplicando funciones de activación como ReLU, sigmoide o tanh (Nielsen, 2015).
- Capa de salida: genera la predicción final del modelo.
Cada neurona está conectada a otras, a través de pesos sinápticos; estos se ajustan mediante algoritmos de entrenamiento, como descenso de gradiente estocástico (SGD) o Adam (Kingma & Ba, 2015).
Tipos de redes neuronales:- : se compone de múltiples capas y es entrenado con el algoritmo de retropropagación (Rumelhart, Hinton, & Williams, 1986).
- Redes convolucionales (CNNs): especializadas en el procesamiento de imágenes, utilizan capas convolucionales para detectar patrones en diferentes escalas (LeCun et al., 1998).
- Redes recurrentes (RNNs): diseñadas para procesar secuencias de datos, como textos o series temporales (Hochreiter & Schmidhuber, 1997).
- Redes profundas (Deep Learning): son redes con muchas capas ocultas, lo que permite aprender representaciones más complejas de los datos (Goodfellow et al., 2016).
Aplicaciones de las redes neuronales:Las redes neuronales han revolucionado diversas áreas, entre ellas:
- Visión por computadora: en tareas como reconocimiento facial y conducción autónoma (He, Zhang, Ren, & Sun, 2016).
- Procesamiento de lenguaje natural (NLP): se usan en traductores automáticos y asistentes virtuales (Vaswani et al., 2017).
- Medicina: diagnóstico de enfermedades mediante el análisis de imágenes médicas (Esteva et al., 2017).
Revisión de regresión lineal y logísticaA continuación, repasamos dos algoritmos básicos de machine learning para regresión y clasificación respectivamente. En esencia, para ambos casos se tienen features de entrada, a los cuales se les asigna un peso y se aplica una función para obtener una salida.
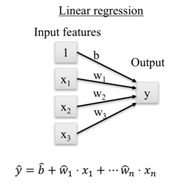
Figura 4. Regresión lineal. 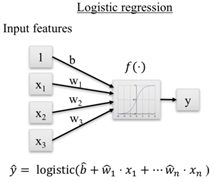
Figura 5. Regresión logística.
Perceptrón multicapa con una capa ocultaEl (MLP, Multi-Layer Perceptron) es un tipo de red neuronal artificial que consiste en múltiples capas de neuronas organizadas en una estructura jerárquica, lo que le permite modelar relaciones no lineales en los datos (Goodfellow, Bengio, & Courville, 2016). Se considera una extensión del perceptrón simple, introducido por Rosenblatt en 1958, pero con la inclusión de una o más capas ocultas, que mejoran su capacidad de aprendizaje (Rosenblatt, 1958).
Arquitectura del MLPEl MLP está compuesto por tres tipos de capas principales:
- Capa de entrada: recibe los datos y los pasa a la siguiente capa sin modificaciones (Nielsen, 2015).
- Capas ocultas: responsables de procesar la información aplicando funciones de activación como sigmoide, tangente hiperbólica (tanh) o ReLU (Nielsen, 2015).
- Capa de salida: genera la predicción final, dependiendo del problema, aplicando funciones como softmax en clasificación o activación lineal en regresión (LeCun, Bengio, & Hinton, 2015).
La Figura 6 ilustra el proceso que sigue el perceptrón multicapa:
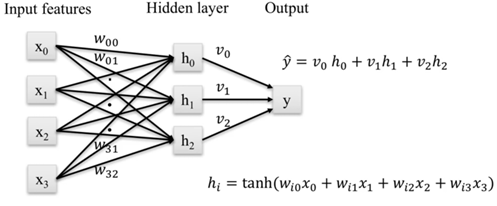
Figura 6. Perceptrón multicapa.
Funciones de activaciónLas funciones de activación son fundamentales en las redes neuronales, ya que permiten la introducción de no linealidad en el modelo y facilitan el aprendizaje de patrones complejos en los datos (Goodfellow, Bengio, & Courville, 2016). Dos de las funciones más utilizadas en redes neuronales profundas son ReLU (Rectified Linear Unit) y tanh (tangente hiperbólica).
Función de activación ReLU (Rectified Linear Unit)La función ReLU se define matemáticamente como:
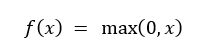
Figura 7. Función de activación ReLU. Esto significa que cualquier valor negativo se convierte en 0, mientras que los valores positivos permanecen sin cambios (Nair & Hinton, 2010). Esta propiedad hace que ReLU sea computacionalmente eficiente y ayude a mitigar el problema del desvanecimiento del gradiente, un inconveniente común en redes profundas (Glorot, Bordes, & Bengio, 2011).
Ventajas de ReLU:- Evita el desvanecimiento del gradiente para valores positivos, permitiendo un entrenamiento más eficiente (Goodfellow et al., 2016).
- Computacionalmente eficiente, ya que solo requiere una comparación simple para su cálculo (Nair & Hinton, 2010).
- Introduce esparcidad, ya que algunos valores de activación se convierten en cero, reduciendo el sobreajuste (Glorot et al., 2011).
- El problema de las neuronas muertas: si demasiadas neuronas tienen valores negativos, estas dejan de aprender porque su gradiente se vuelve cero (Maas, Hannun, & Ng, 2013).
- No está centrada en cero, lo que puede generar inestabilidad en la optimización (Glorot & Bengio, 2010).
Función de activación tanh (tangente hiperbólica)La función tanh se define matemáticamente como:
Ventajas de tanh: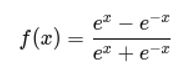
Figura 8. Función de activación tanh. - Centrada en cero, lo que mejora la estabilidad del entrenamiento en comparación con la sigmoide (LeCun et al., 1998).
- Útil para datos con valores negativos y positivos, ya que permite una mejor distribución de las activaciones (Goodfellow et al., 2016).
Desventajas de tanh:- Sufre del problema del desvanecimiento del gradiente, lo que puede dificultar el entrenamiento de redes profundas (Bengio, Simard, & Frasconi, 1994).
- Computacionalmente más costosa que ReLU, ya que requiere operaciones exponenciales (LeCun et al., 1998).
La Figura 9 ilustra la distribución de varias funciones de activación:
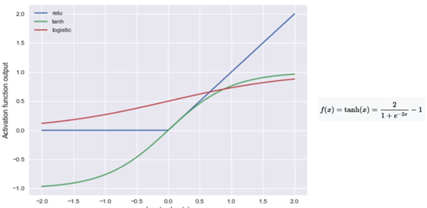
Figura 9. Funciones de activación.
Ventajas y desventajas de las redes neuronalesVentajas Desventajas Se consideran las bases del estado del arte de modelos que incluyen arquitecturas avanzadas que capturan, de forma efectiva, la complejidad de los features dada la suficiente data y poder de cómputo. Modelos más complejos requieren más tiempo de entrenamiento, así como mayor customización. Se necesita un preprocesamiento de datos cuidadoso. Es buena opción cuando los features son de tipos similares; pero mala cuando los features son de diferente tipo. Parámetros importantes para MLPClassifiers y MLPRegressorsVentajasSe consideran las bases del estado del arte de modelos que incluyen arquitecturas avanzadas que capturan, de forma efectiva, la complejidad de los features dada la suficiente data y poder de cómputo.DesventajasModelos más complejos requieren más tiempo de entrenamiento, así como mayor customización.
Se necesita un preprocesamiento de datos cuidadoso.
Es buena opción cuando los features son de tipos similares; pero mala cuando los features son de diferente tipo.- hidden_layer_sizes: configura el número de capas ocultas y de neuronas por capa.
- alpha: controla el peso en la penalización por regularización, que reduce los pesos a 0.
- activation: controla la función no lineal usada para definir la función de activación (ReLU, logistic, tanh).
Data leakage ocurre cuando los datos que se están usando para entrenar contienen información sobre lo que se está tratando predecir. Introducir información sobre el target durante el proceso de entrenamiento no es legítimamente adecuado. A continuación, cito algunos ejemplos obvios.
- Usar el target como un feature más.
- Incluir datos de testeo en el conjunto de datos de entrenamiento.
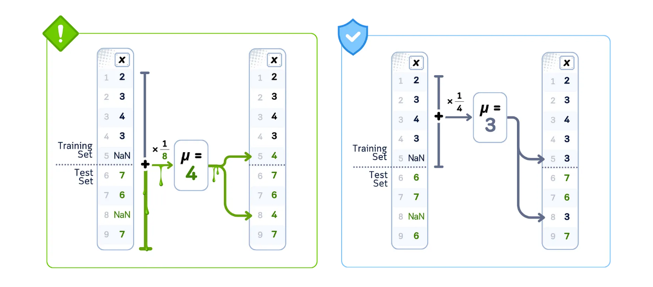
Si el performance de tu modelo es ‘demasiado bueno’, muy probablemente se deba a un tema de data leakage. A continuación, se muestra una ilustración a modo de ejemplo de usar todo el dataset para calcular el promedio:
Ejemplos sutiles de data leakage- Target: usuario se queda o no en la página web. Giveaway feature: duración de la sesión con base en información acerca de futuras visitas.
- Target: predecir si un usuario en un banco es propenso a abrir una cuenta. Giveaway feature: el número de cuenta solo se llena cuando el usuario abre una.
- Cualquiera de estas leaked features es altamente predictiva del target, pero no estará legítimamente disponible cuando la nueva predicción se tenga que realizar.
Otros ejemplos de data leakageAprende más
Para conocer más sobre Data Leakage , puedes leer el siguiente artículo ¡Accede aquí!
Leakage en los datos de entrenamiento:
- Realizar tareas de preprocesamiento usando parámetros calculados a partir de usar el dataset completo.
- En series de tiempo: cuando se usan registros de datos futuros al momento de realizar una nueva predicción.
- Errores en la adquisición de datos o cuando se usan valores que indican ausencia de datos (e.g. el valor de 999) puede encriptar información sobre valores faltantes que revelan información acerca del futuro.
Leakage en features:- Eliminar variables que no son legítimas, sin eliminar variables que encriptan la misma información o información relacionada.
- Deshacer randomización intencional, que releva información específica acerca del target.
Detectar data leakage:- Antes de construir el modelo:
- Realizar un análisis exploratorio de datos para encontrar posibles sorpresas en los datos.
- ¿Los features están altamente correlacionados con el target?
- Después de construir el modelo:
- Buscar features que tengan algún comportamiento sorpresivo en el modelo entrenado.
- ¿Hay features que tienen un peso muy alto o alto, information gain?
- ¿El performance final del modelo es sorpresivamente muy alto comparado con el performance de modelos similares?
- Limitaciones en el deployment de los modelos:
- Potencialmente costoso en términos de tiempo de desarrollo, pero más realista.
- ¿El modelo entrenado generaliza bien con nuevos datos?
Aprende más
Para conocer más sobre The Theachery of Leakage , puedes leer el siguiente artículo ¡Accede aquí!
Minimizar el data leakage- Realizar data preparation con cada fold de cross validation por separado.
- Cuando se trabaje con series de tiempo, usar timestamp.
- Antes de trabajar con un nuevo dataset, se divide un dataset de validación final.
Profundiza más
Este recurso te ayudará a enfatizar sobre Implementación en Python de carga y visualización de datos que no son linealmente separables ¡Accede aquí!
-
Hacer un envío
-
Hacer un envío